Как создать контент для AI ответов
Пошаговая инструкция по контент планированию, изучению логики поисковой шины OpenAI и других моделей и оптимизация контента для показа ссылок источников в AI ответах
Уже сегодня GPT дает небольшой прирост трафика, но его основная сила — в очень высокой доле конверсии. Все видят в подобном контенте будущее — ведь в SEO мы идем не только за трафиком, но и за продажами. Львиная доля бизнесов не зарабатывает на рекламе, она ее подает. И поэтому актуальность проблемы высока.
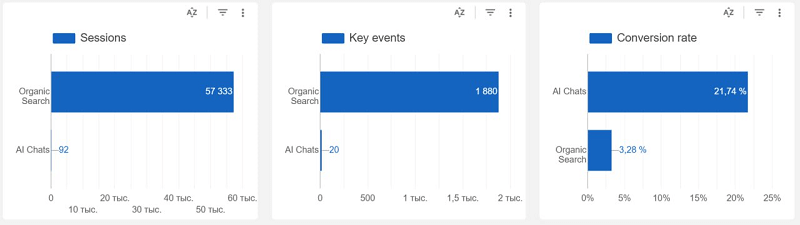
AI трафик пока что не может похвастаться огромными показателями продаж, но он может продемонстрировать высокие показатели коэффициента конверсии. Он местами в 7 раз больше, чем у органического трафика!
Пусть и в Ecommerce органика и GPT дают небольшой разброс. Причина — аудитория все равно еще “гуглит” и ищет цену, но это ненадолго. Важно, по каким запросам вы ловите “трафик”. К сожалению, эти данные отследить нельзя, но можно узнать, по каким страницам пользователи “приходят” на ваш сайт в аналитике. Такие страницы — на вес золота. В этой статье я постараюсь рассказать, как GPT ищет контент и выводит в результатах ответов.
Как работает поиск в GPT?

Когда вы задаёте запрос, GPT использует внутреннюю модель, то есть знания, полученные в процессе обучения на огромных объёмах текстов. Это охватывает большую часть случаев — примерно 85-95% всех ответов. В этой зоне он опирается на обобщённую статистику, закономерности и факты, усвоенные до июня 2024 года (на момент системы GPT 4o).
Если информация устарела, зависит от актуальных событий или требует локальной специфики (например, расписание мероприятий, цены, наличие товаров, свежие законы и т.п.), GPT запускает поиск в интернете — но только если вы разрешили, или явно включили инструмент веб-поиска. В этих случаях внутренняя модель отправляет поисковый запрос, анализирует результаты и формирует ответ.

Что касается поисковых систем — при активации веб-инструмента используется поисковый агрегатор с доступом к основным источникам (включая Google, Bing и др.). Однако запросы не отправляются напрямую от имени GPT к конкретным поисковикам. Это проксируется через специально настроенную инфраструктуру OpenAI.
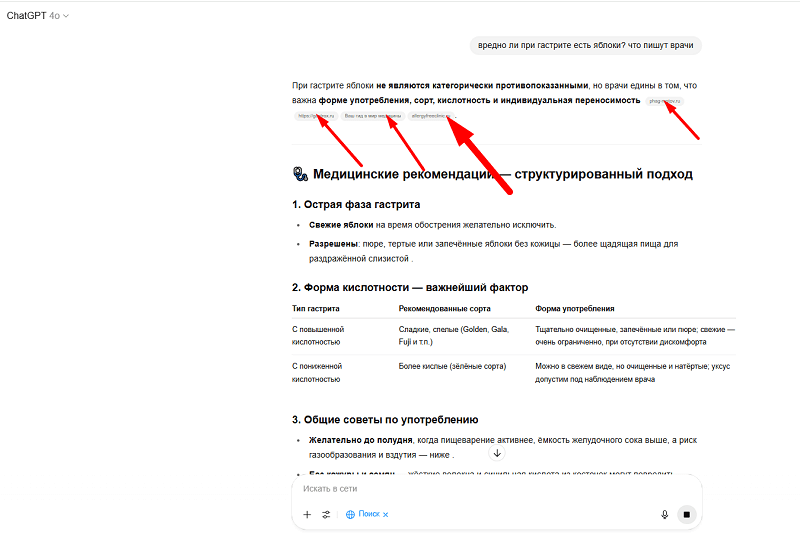
Иногда в результатах ответа он не выводит источники данных. Так бывает, в довольно простых ответах.

Итого поиск запускается, если тематика контента:
- отсутствует в базе AI по каким-либо причинам;
- достаточно локальна;
- требует актуальных данных.
Как GPT строит поисковый запрос?
По умолчанию основной текст запроса — английский язык. Почему? Да потому что он дает максимальный охват релевантных и первичных источников (документация, официальные блоги, международные СМИ). Да и алгоритмы поисковиков (в частности Google) более точно ранжируют англоязычные результаты по техническим, профессиональным и обучающим темам.
Но локальный язык тоже возможен (русский, украинский, польский), когда вопрос касается локального законодательства, новостей, кейсов, локальных инструментов.
Вторая причина — когда искомый контент преимущественно создаётся на русском (например, нишевые отрасли, региональные рынки). Я задал запросы, по какой схеме он бы искал новости в Одессе, и вот что он мне ответил.

Вы можете попрактиковаться, просто настроив промт так:
<Тут ваш промт, к примеру какие новости в Одессе за сегодня
затем после этого выведи мне текст поисковых запросов, какие ты отправлял в поисковую шину OpenAI>
Также практикуется и гибридный подход. Формируется 2 параллельных запроса — на английском и локальном языке. Далее сравниваются SERP по структуре и глубине контента.
Формирование поискового запроса осуществляется по принципу семантической релевантности и намерения пользователя (search intent). Основной упор — на точную формулировку задачи.
Алгоритм построения запроса следующий:
- Нормализация терминов: устранение омонимов, использование индустриальных синонимов.
- Уточнение сущностей: добавление специфических атрибутов — геолокации, временных рамок, отраслевых терминов.
- Тип запроса:
- информационный (how, what, why, guide, comparison);
- навигационный (официальные сайты, регламенты, спецификации);
- транзакционный (API access, downloads, tools, templates).
- Модификаторы качества:
- site:gov, filetype:pdf, intitle:, inurl: — для суживания выборки по формату и источнику.
- отрицательные операторы -example, -reddit — для отсечения нерелевантных шумов.
Общая схема запроса выглядит так:
[главная сущность] + [уточнение / модификаторы] + [фильтры / операторы]
| Компонент | Цель | Примеры |
| Главная сущность | Ключевое ядро запроса (тема, объект, ошибка) | E-E-A-T, canonical, 301 redirect, CTR model |
| Уточнение | Действие, вопрос или характеристика | update, best practice, comparison, seo impact |
| Модификаторы | Уточнение контекста, типа результата, формата | checklist, guide, whitepaper, case study, vs |
| Операторы фильтрации | Ограничение источников или временного интервала | site:, OR, intitle:, filetype:, after: |
| Отрицание (если нужно) | Исключение лишнего или нерелевантного контента | -reddit, -quora, -forum, -opinion |
Я попросил его расписать примеры, и вот что он мне выдал:
Если необходимо найти последние изменения в алгоритме Google по E-E-A-T, система построит запрос вида:
google E-E-A-T update site:developers.google.com OR site:searchenginejournal.com after:2024-01-01
Если я спросил его, что выбрать Canonical или Noindex – он бы искал так:
canonical tag vs noindex site:moz.com OR site:developers.google.com after:2023-01-01
То есть используется логика расширенного поиска, про которую я писал в статье “Секреты поиска Google”
Зачем GPT ищет по конкретному сайту (site:)? Он решает, когда тема попадает в эти три критерия:
- Нужно получить официальную точку зрения (например, Google, Meta, Microsoft).
- Сайт содержит экспертные или структурированные материалы, которые проще фильтровать по его внутреннему контенту.
- Надо обойти внешние интерпретации и SEO-шум.
Но нас интересует чаще всего второй вариант – когда он ищет по всему интернету.
А это сработает в трех случаях:
- Тема нишевaя, малоизвестнaя или новая — и неизвестно, кто её освещал.
- Требуется многообразие точек зрения (мнения, кейсы, сравнения).
- Важно оценить информационный шум и уровень конкуренции по запросу.
Где происходит запрос?
Самое интересное — что GPT не использует одну поисковую систему. Об этом мало кто говорит, но факт остается фактом — запрос отправляется не напрямую в поисковик, а в поисковую шину OpenAI.
Она:
- Получает результаты из одного или нескольких агрегированных источников (в том числе Google, Bing, DuckDuckGo и др.).
- Отбирает от 3 до 10 результатов по запросу.
- Удаляет нерелевантные или потенциально небезопасные страницы.
- Поднимает в приоритете официальные, авторитетные источники (например, gov-сайты, ведущие СМИ и пр.)
И здесь нюанс — чтобы наш контент ранжировался по подобной логике построения запросов и в ТОП10 в нижеперечисленных поисковых системах.
| Поисковик / Ресурс | Назначение |
| Основной универсальный источник | |
| Bing | Альтернативный источник, устойчив к геоблокировкам |
| DuckDuckGo | Быстрые проверки, минимизация кэшированных шумов |
| Google Scholar | Для академических и патентных публикаций |
| You.com / Neeva (при наличии) | Контекстуализированный поиск, минимизация SEO-шума |
| Niche-сайты (StackOverflow, Reddit, GitHub, SEJ) | Отраслевая экспертиза |
В выдаче фильтруется определенная выборка по подобным запросам:
- Топ-5 результатов — обязательный анализ. Нахождение контента в ТОП5 будет нашей целью.
- 6-10 позиции — если запрос редкий, нишевый или требует альтернативных точек зрения. Тут если в выдаче толком трудно что-то найти.
- >10 позиции — анализируются только при явном дефиците релевантного контента (long-tail queries). Такое почти не бывает в обычных запросах.
Как отбираются результаты поиска?
На этом моменте линкбилдерам напрячься. Да и контент-мейкерам — тоже.
Приоритет для “изучения” материала уходит на следующие виды сайтов.
- Официальные домены — *.gov, *.edu, *.org, сайты компаний-разработчиков, стандартизирующих организаций (W3C, ISO, IETF).
- Профильные СМИ — Search Engine Land, Moz, Ahrefs, SEMrush, SEJ. (если брать мою тематику).
- Форумы/StackOverflow/GitHub — при технических вопросах.
- Тематические блоги — только при перекрёстной валидации с первоисточниками.
Наличие вашего авторского контента на подобных площадках — мастхев.
Но что делать, если тематика в этом направлении — не раскрыта?
Что важно для качества контента в GPT?
Само собой, шутки про то, откуда тащит GPT ответы, у SEO специалистов уже давно на слуху. Львиная доля российских сайтов для Украины — это уже не норма, а какой-то кошмар.
Но если в запросе, конечно, указывать страну, то да — он будет стараться выбирать конкретные сайты этой страны.
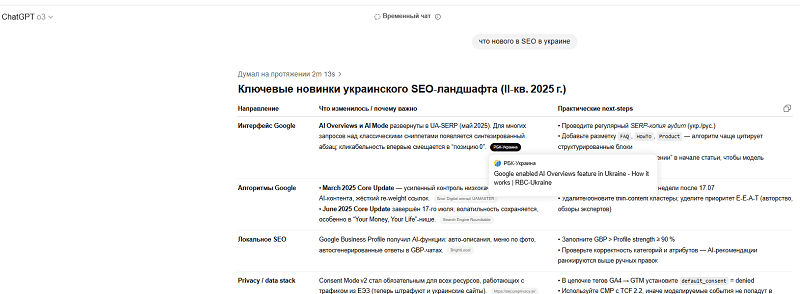
Я спросил GPT, по какой логике он “фильтрует” результаты, и вот что узнал.
- Дата публикации — не старше 12 мес. для технологических тем.
- Авторство — нужно, чтобы было прописано имя эксперта или указана организация (в микроразметке Schema.org).
- Высокий авторитет домена (да, у него есть база метрик, он по ней сверяется).
- Структура и метаданные — здесь азбука: четко прописанный H1, иерархия H2-H3, наличие таблиц и цитат приветствуется.
- Исходящие ссылки на официальные источники. Да, те самые, которые никто не любит у себя ставить.
Как GPT интерпретирует найденные результаты?
Если вы думали, что он нашел ваш URL и тут все ок — я вас расстрою. Первое, что он делает, это анализирует сниппет: если он точно отвечает на запрос — данный сайт будет открыт.
Важное замечание. OpenAI и аналогичные LLM-системы не “видят” сниппеты напрямую из Google в реальном времени.
Запрос направляется в поисковую систему (например, Bing или Google Custom Search API). Затем возвращается JSON с полями:
- title
- snippet или description
- url
То есть корректное прописывание уже может гарантировать попадание вашего URL в его ответ, если ваши метаданные и даже URL (ЧПУ) отражают:
- полноту ответа,
- соответствие вопросу,
- уникальность / повторяемость среди других фрагментов в выдаче.
Модель читает именно этот фрагмент (snippet), как основной источник первого контакта с информацией.
Прописывать и проверять метаданные можно в нашем инструменте Unmiss Website Audit, где можно просмотреть сниппет и отредактировать ваши метаданные.
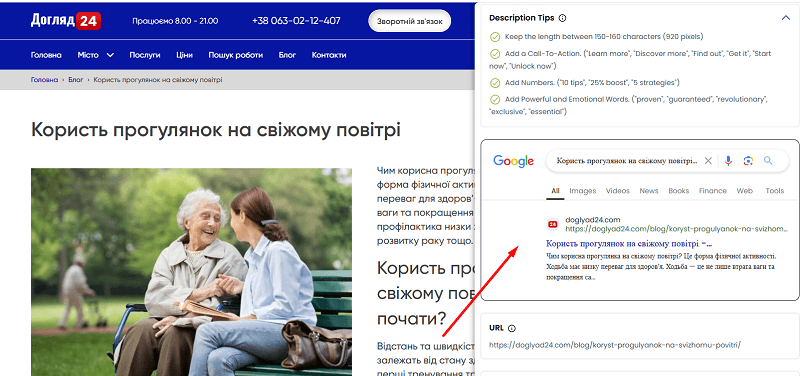
Интересный факт. Если сниппет содержит высокорелевантный и завершённый ответ, модель скорее пропустит этот URL, как уже “отработанный” — не будет открывать – а просто учтет это как ответ. Но если сниппет частично релевантен, но содержит незавершённость, вопрос или недосказанность, модель с большой вероятностью откроет сайт, чтобы дочитать и “понять до конца”.
Делайте сниппет достаточно релевантным, но оставляйте в нём пробел в знаниях, особенно для сложных или экспертных тем.
Затем происходит семантический парсинг контента и данных. Система способна агрегировать данные из нескольких источников для создания синтеза информации. В итоге если инфа устарела или противоречива, выводится метка: “требует подтверждения”, данные игнорируются в анализе.
Семантический парсинг — это не просто анализ текста, а многоуровневая интеллектуальная обработка информации, направленная на:
- получение достоверных, проверенных фактов;
- создание связной картины на основе фрагментов из разнородных источников;
- обеспечение гибкости и адаптивности при автоматическом принятии решений (например, в системах рекомендаций или аналитики трендов).
Разберем, как происходит сам парсинг контента и данных:
- Первоначально контент очищается от разметки, HTML-тегов, JS и неинформационного шума.
- Затем проводится лемматизация, удаление стоп-слов, приведение к единому формату (даты, числа, единицы измерения).
Для этого применяются технологии Named Entity Recognition (NER), Part-of-Speech Tagging (POS), Dependency Parsing, Semantic Role Labeling (SRL).
Зачем они нужны? Чтобы определить ключевые сущности: имена, компании, продукты, категории, построить связи между объектами (кто что сделал, когда и с каким результатом) и распознать тональность, контекст, уровень достоверности.
Как выбирать тему для GPT ответов?
Учитывая все вышеперечисленное, вам нужно будет освоить логику построения запросов в вашей нише. Это сложно, но в целом требует лишь немного времени. Задача — собрать все хвосты запросов и попробовать “сгенерировать” по ним запросы для поисковых систем.
- Проверьте топ‑5 SERP по ключевому запросу: есть ли незакрытые вопросы, устаревшие данные или отсутствие локального угла.
- Ищите темы, где GPT делает вынужденный веб‑поиск (недостаток знаний после июня 2024 г.)
Я рекомендую освоить наш простой инструмент генератора запросов.
Как примеры могут быть такие запросы:
- High‑intent long‑tail: «как выбрать {продукт} 2025», «шаги внедрения {технология} в Украине». Также сюда попадают всегда новые релизы, изменения стандартов, локальные кейсы — то, что не закрепилось в базе LLM. Это всегда будет “гуглиться”.
- Готовые ключевые слова просто проверяем в выдаче и смотрим, что есть там. В будущем я доработаю инструмент и это можно будет сделать в пару кликов.
Смотрите, есть ли контент. Если он есть — пропускайте запросы. Если его нет или он мусорный — это наша тема для материала.
Напоминаю, запросы добавляем по гибридному методу: на английском языке и на локальном. Сформулируйте и английскую, и русскую/украинскую версию ключевой фразы; убедитесь, что обе отражают ту же сущность.
Далее сразу структурируйте тему сразу под будущие подзаголовки. Используйте micro‑outline (H2‑H3‑H4) ещё до написания текста и старайтесь, чтобы каждый H2 отвечал на конкретный под‑intent (гайд, сравнение, подборка, чеклист). Здесь отлично подойдет любой майдмап сервис для работы.
Далее переходим к метаданным. И здесь нам поможет наш калькулятор заголовков.
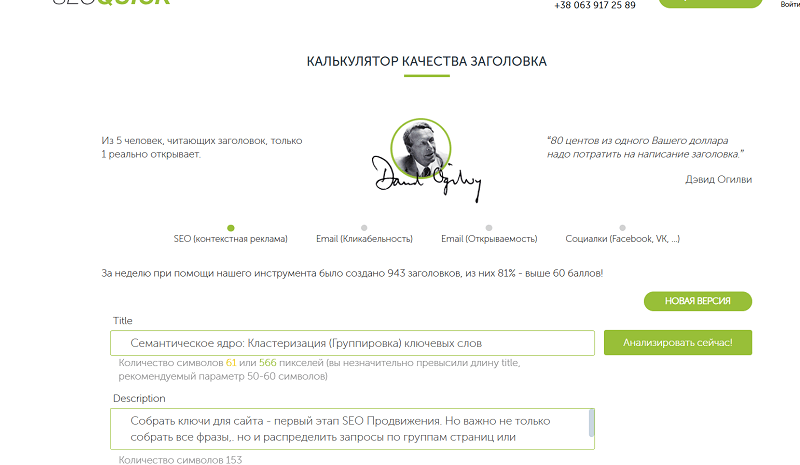
- Title — включите главную сущность + уточнение действия/ценности + год, если релевантно. Старайтесь выдержать длину в 61 символ.
- Description — кратко ответьте на intent и оставьте «недосказанность», чтобы LLM перешла на сайт.
- H1 — повторяет тему, но без шаблонных слов “Гайд”, “обзор”. То есть просто главный ключ.
Другие моменты, которые обязаны присутствовать на странице:
- OG‑теги / Twitter Cards — дублируйте Title + эмоциональный призыв, добавьте релевантное изображение 1200×630 px.
- Schema.org Article — обязательно указать author, datePublished, headline, publisher.logo.
- OG микроразметка для автора и других элементов.
URL тоже стараемся делать проще простого — коротко, без стоп‑слов, латиница, дефис‑разделитель. Помните про семантическую предсказуемость: пусть по URL сразу понятно, что шина ИИ тут найдёт, и избегайте аморфных /blog/post-123.
Что делать с годом? Для ежегодных тем используйте /topic-2025/. Не забываем потом делать редирект 301 со старого /topic-2024/. Для вечнозеленых материалов — без года и с датой обновления в Schema.org. Ну и не забываем обновлять материал ежегодно.
Про уровень вложенности URL — максимум 3 уровня вложенности. То есть папка, подпапка, страница. Дальше не нужно углублять структуру URL.
/seo/technical/canonical-vs-noindex
Логическая иерархия помогает LLM понять контекст «родитель > дочерний материал».
Также важно чтобы тут уже была учтена локаль — префикс языка /uk/, /ru/, или поддомен uk.example.com, чтобы GPT выбрал нужную локаль при запросе.
Следуя этой схеме, вы максимизируете шанс попасть в те 3‑10 результатов, которые GPT‑шина действительно просматривает, а не только показывает в сниппете.
Как контент попадает в AI Overviews и Perplexity в 2026
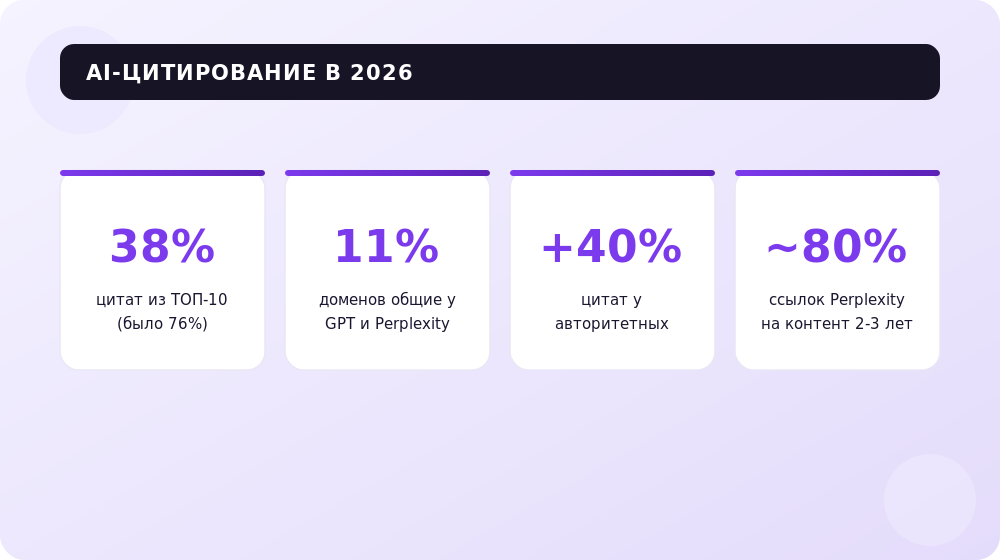
Логика GPT‑шины — это только половина картины. В 2026 году основной поток AI‑трафика идёт через Google AI Overviews и Perplexity, и здесь правила немного другие. Главный сдвиг: попадание в ТОП‑10 органики больше не гарантирует цитирование. По данным исследования Ahrefs, доля цитат в AI Overviews из страниц ТОП‑10 упала с 76% (середина 2025) до 38% к началу 2026 — остальное приходится на страницы с позициями 11–100 и даже глубже. Причина — query fan‑out: Google разбивает ваш запрос на десятки подзапросов и цитирует те страницы, которые чаще всего всплывают по всему этому вееру, а не только по основному ключу. Поэтому важно закрывать не один интент, а весь куст связанных вопросов на одной странице — ровно та логика гибридных запросов и micro‑outline, о которой мы говорили выше. Глубже разбор механики мы дали в материале по GEO‑оптимизации сайта под GPT.
Perplexity устроен иначе: каждый ответ по умолчанию содержит пронумерованные ссылки на источники, и платформа крайне чувствительна к свежести и авторитету. По данным анализа 366 000+ цитат (исследование Kai‑Cheng Yang, 2025), около половины ссылок Perplexity ведут на материалы 2025 года, а ~80% — на контент за последние 2–3 года; высокоавторитетные домены получают до 40% больше цитат, чем рядовые блоги. При этом пересечение источников между платформами минимально — около 11% доменов цитируются и в ChatGPT, и в Perplexity одновременно, поэтому ставку нужно делать на универсальные сигналы: четкая структура с прямым ответом в первых 30% страницы, регулярное обновление даты, экспертное авторство в Schema.org и подтверждение фактов внешними источниками. Готовый набор формулировок для проверки своих страниц под разные модели мы собрали в подборке 50 мега‑промтов для ChatGPT и Gemini под SEO.
Результаты
При должном уровне качества контента, правильном прописывании метаданных ваши сайты будут расти и давать результаты в ИИ ответах всегда.
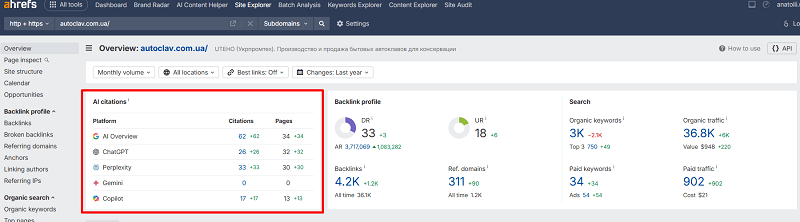
Вне зависимости от ниши, будь то производство, медицина, или что-то еще.
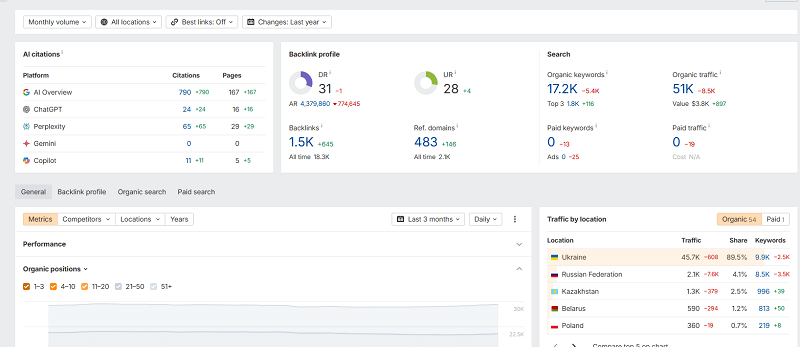
В медицинской нише при должном качестве контента и семантической проработке страниц можно добиваться действительно огромных результатов с минимальными усилиями, ведь для этого вам не нужны ссылки с бирж или краудмаркетинг, а лишь ювелирная работа с контентом и правильный PR.

Услуги SEO продвижения в ИИ
Если вы хотите заказать услуги SEO продвижения в ИИ, заполните эту форму и забронируйте консультацию, мы обсудим с вами стратегию по созданию контента, который любит ИИ.

Merchant Center под AI Mode: как товарный фид готовить к разговорному шопингу в 2026
Google AI Mode меняет товарный поиск: обычного фида уже мало. Разбираем новые атрибуты Merchant Center, за что банят магазины и с чего начать владельцу.
Читать →
Оптимизация изображений для SEO: alt, размеры и вес под Core Web Vitals
Как оптимизировать изображения для SEO в 2026: зачем нужен alt, почему width и height убирают скачки вёрстки (CLS), какие форматы (WebP, AVIF) и как не сломать LCP ленивой загрузкой. Разбор от SEOquick.
Читать →
Search Everywhere Optimization: продвижение в TikTok, YouTube, Reddit и AI-поиске
Клиент ищет вас не только в Google: 49% потребителей ищут в TikTok, Reddit получает 842 млн кликов из Google в месяц, YouTube — источник каждой четвёртой ссылки в AI Overviews. Разбираю, как владельцу бизнеса выбрать 2–3 площадки и не распылить бюджет.
Читать →Хотите применить это к своему сайту?
Разберем текущую ситуацию, найдем первые точки роста и предложим формат работы без лишней теории.
