Дубли контента: тихий убийца трафика — как находить и устранять
Google не выдаёт штраф за дубли контента — но именно они тихо съедают ваш трафик. Разбираю, какие бывают дубли, почему они размывают сигналы и мешают AI-поисковикам, и как находить и устранять их через Search Console и Screaming Frog.
Google не штрафует сайт за дубли контента — но это не значит, что они безопасны. Дубли размывают ссылочные сигналы, съедают краулинговый бюджет и мешают AI-поисковикам определить вас как источник. По оценке Google, до 25–30% всего контента в сети — дубликаты, и почти всегда это техническая ошибка, а не злой умысел.
Вокруг дублирующего контента в SEO-сообществе до сих пор путаница: одни пугают «баном», другие машут рукой — мол, Google сам разберётся. Правда посередине, и она важнее, чем кажется. Ниже разбираю тему по видео с нашего канала SEOquick: что считается дублем, почему он убивает органику и как его находить и устранять — с цифрами и источниками.

Что считается дублем контента
Глазами Google дублей всего четыре вида, и лечатся они по-разному:
1. Технические внутренние дубли. Одинаковый контент на разных URL внутри одного сайта: страницы с параметрами (?utm=, фильтры, сортировки, ?page=), пустые шаблонные страницы без метаданных, пагинация, теги и категории блога, которые движок генерирует автоматически.
2. Хостинг-дубли. Ошибки конфигурации сервера: нет редиректа с HTTP на HTTPS или с www на без-www. В итоге у вас существуют полностью идентичные версии сайта на разных протоколах и поддоменах.
3. Собственные внешние дубли. Ваш контент, который вы сами разложили по нескольким доменам — например, один и тот же пресс-релиз или описание на разных проектах.
4. Внешние дубли от третьих лиц. Копии вашего контента на чужих доменах без вашего ведома: RSS-парсинг, репосты пресс-релизов, рерайты и откровенное воровство.

Штрафует ли Google за дубли контента?
Короткий ответ: нет, отдельного штрафа за дубли не существует. Джон Мюллер из Google не раз повторял: сайт не наказывается за дублирующийся контент — поисковик просто кластеризует похожие страницы и выбирает одну для показа, а остальные не показывает. Это подтверждает и документация Google: система склеивает дубли и выбирает канонический URL сама.
Минус в том, что вы не узнаете, какую страницу Google скрыл и почему. И здесь ключевой нюанс, который на видео формулирует Николай:
«Вроде бы сам Google вам не вредит, но его система расчёта алгоритма для вашего сайта вредит. И каждая дублирующаяся страница, которая попадает в индекс по вашей ошибке, в целом понижает рейтинг вашего ресурса».
То есть формально «минуса» к сайту не добавляют, но суммарный вес сайта размывается по десяткам мусорных страниц. Отдельная история — массово скопированный внешний контент: он снижает воспринимаемое качество сайта и ранжируемость по конкурентным запросам. Вывод простой: дубли — это серьёзная техническая ошибка, которая бьёт по продвижению стратегически.
Почему дубли тихо убивают органику
Дубли не роняют сайт одномоментно — они делают это незаметно, по трём направлениям:
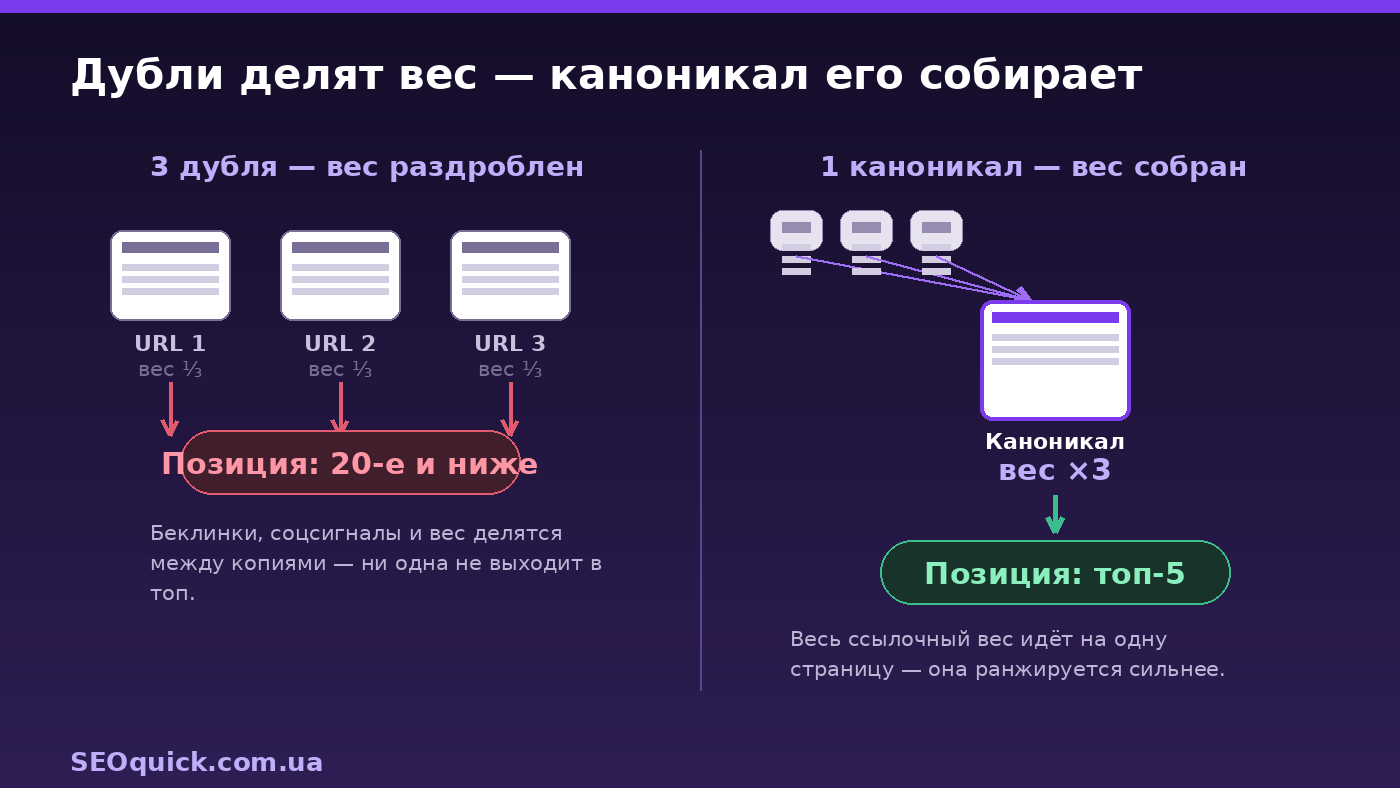
Размывание сигналов. Когда один и тот же материал доступен по нескольким URL, поисковик распределяет ранжирующие сигналы между версиями вместо того, чтобы собрать их в одну сильную страницу. Беклинки на разные дубли не суммируют авторитет, а расшары в соцсетях рассеиваются по копиям. По данным отраслевых оценок, сайты с заметными проблемами дублей теряют на 15–20% органического трафика относительно похожих сайтов с корректной канонизацией.
Краулинговый бюджет. Робот тратит обходы на бесполезные копии вместо ваших рабочих страниц — новые материалы индексируются медленнее.
Невидимость для AI-поиска. Это новый и недооценённый риск 2026 года. ChatGPT, Perplexity и Claude при генерации ответов выбирают авторитетный, уникальный источник. Когда ваш контент фрагментирован по нескольким URL, AI-система не может однозначно определить вас как первоисточник — и цитирует конкурента. О том, как в принципе попадать в AI-ответы, мы писали в гайде по GEO-оптимизации сайта под GPT.
Как находить дубли: 3 рабочих способа
1. Поисковые операторы. Самый быстрый способ прикинуть масштаб. Через site:вашдомен inurl:page найдёте страницы пагинации в индексе, через site:вашдомен intitle:"фрагмент заголовка" — страницы с одинаковыми тайтлами. Часто именно так всплывают мусорные версии на чужом поддомене.
2. Screaming Frog (или аналог). В отчёте Content → Near Duplicates инструмент показывает страницы с высоким сходством контента. В отличие от проверки грамматики, этот отчёт не врёт: он реально находит страницы, где контента слишком мало или он почти повторяется. А мало контента — это и есть частая причина, почему страницы плохо ранжируются.
3. Google Search Console. Самый честный источник. Раздел «Индексирование страниц» → блок «Почему страницы не индексируются». Смотрим два статуса:
— «Страница является копией. Канонический вариант не выбран пользователем» — Google посчитал страницу дублем, а вы не указали canonical.
— «Страница является копией. Google выбрал канонической другую страницу, чем указано пользователем» — вы прописали canonical, но Google с вами не согласился (см. гайд Google по устранению). Чаще всего Google прав — стоит перепроверить логику канонизации.
Как устранять дубли контента
После того как дубли найдены, решаем по типам:
301-редиректы. Для хостинг-дублей — единственный правильный путь: HTTP → HTTPS, www → без-www, все зеркала на одну версию. Внутренние ссылки проставляем только на канонический вариант, в Search Console добавляем только его.
Canonical. Ставьте self-referencing canonical на каждую страницу (даже на саму себя) и cross-domain canonical, если легально републикуете чужой материал. Важно: не указывайте разные канонические URL разными методами (один в sitemap, другой в rel=canonical) — Google запутается. Для синдикации Google рекомендует не canonical, а запрет индексации копии у партнёра.
Hreflang для языковых версий. Наш сайт двуязычный (RU/UA), и без hreflang версии на похожих языках Google может счесть дублями. В <head> прописывается основной язык и альтернативные плюс x-default. Подробнее — в материале про технический SEO для украинских сайтов.
Robots и удаление мусора. Параметрические страницы (UTM-метки, фильтры) закрывайте правилами в robots.txt; технические страницы, которые вообще не должны существовать, — удаляйте и отключайте саму возможность их генерации.
Dev-версии — на пароль. Классический провал — забытая в индексе тестовая версия сайта. Здесь Николай категоричен:
«Закрывайте Dev-версию исключительно на логин-пароль. Noindex страничке тоже вам не поможет, я вам гарантирую».
DMCA против воровства. Если ваш авторский контент воруют, подключите DMCA-защиту: сервис напрямую работает с Google по нарушению авторских прав. Плюс публикуйте материалы первыми — так Google зафиксирует источником именно вас.
Частые вопросы про дубли контента
Штрафует ли Google за дубли контента?
Нет, отдельного штрафа нет. Google кластеризует похожие страницы и показывает одну. Но дубли размывают сигналы и краулинговый бюджет, из-за чего сайт ранжируется хуже.
Сколько дублей — это уже проблема?
Проблема не в количестве, а в том, что дубли попадают в индекс и конкурируют между собой. Даже несколько параметрических копий важной страницы уже дробят её вес.
Canonical или 301 — что выбрать?
Если дублирующий URL не нужен пользователю — 301-редирект (сильный сигнал). Если страница нужна (например, версия с фильтром), но не должна ранжироваться — canonical на основную.
Влияют ли дубли на попадание в AI-ответы?
Да. Фрагментированный по разным URL контент мешает ChatGPT, Perplexity и Claude определить вас первоисточником, снижая шанс цитирования.
Дубли контента — это не про «бан от Google», а про медленную утечку трафика, которую легко не заметить. Найдите их через Search Console и Screaming Frog, склейте редиректами и каноникалами — и вес сайта соберётся туда, где он работает. Если хотите проверить свой сайт на дубли, пришлите нам адрес сайта — сделаем бесплатный аудит.

Агентный SEO в 2026: как AI-агенты выполняют SEO-задачи за вас
Что такое агентный SEO (agentic SEO) и какие задачи AI-агенты уже делают сами: ресёрч, оптимизация, мониторинг. Реальные примеры, цифры 2026 и предупреждение Gartner — разбор от SEOquick.
Читать →
AI-контент и Google в 2026: за что реально штрафуют (спойлер — не за ИИ)
Google не наказывает текст за то, что его написал ИИ — это официальная позиция. Разбираю, что такое scaled content abuse, что изменилось после апдейтов 2026 года и как публиковать AI-контент так, чтобы он ранжировался.
Читать →
Google AI Mode в 2026: что это и как готовить сайт к разговорному поиску
Что такое Google AI Mode, почему падает CTR и как попадать в его ответы. Разбор от SEOquick: 1 млрд пользователей, 93% запросов без клика и рабочий чек-лист на 2026 год.
Читать →Хотите применить это к своему сайту?
Разберем текущую ситуацию, найдем первые точки роста и предложим формат работы без лишней теории.