How to Create Content for AI Answers
A step-by-step guide to content planning, understanding the logic of the OpenAI search backbone and other models, and optimizing content so your source links appear in AI answers
Even today, GPT delivers only a modest traffic bump, but its real strength is an exceptionally high conversion rate. Everyone sees this kind of content as the future — because in SEO we chase not just traffic but sales. The vast majority of businesses don't earn from advertising; they pay for it. And that's exactly why the problem matters so much.
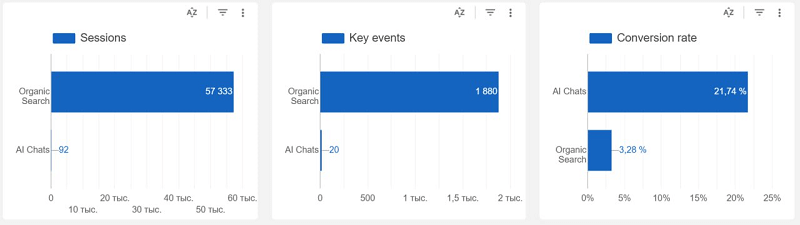
AI traffic can't yet boast huge sales figures, but it can show impressive conversion rates. In some cases it's up to 7 times higher than organic traffic!
Granted, in ecommerce organic and GPT show a small gap. The reason is that the audience still "googles" and shops around for prices — but not for long. What matters is which queries you're catching that "traffic" on. Unfortunately, you can't track that data directly, but you can see in your analytics which pages users "land" on from your site. Those pages are worth their weight in gold. In this article, I'll try to explain how GPT finds content and surfaces it in its answers.
How does search work in GPT?

When you submit a query, GPT uses its internal model — that is, the knowledge it absorbed during training on enormous volumes of text. This covers most cases — roughly 85–95% of all answers. In this zone, it relies on generalized statistics, patterns, and facts learned up to June 2024 (as of the GPT-4o system).
If the information is outdated, depends on current events, or requires local specifics (event schedules, prices, product availability, fresh legislation, etc.), GPT launches a web search — but only if you've allowed it or explicitly enabled the web search tool. In those cases, the internal model sends out a search query, analyzes the results, and forms an answer.

As for search engines — when the web tool is activated, GPT uses a search aggregator with access to major sources (including Google, Bing, and others). However, the queries aren't sent directly from GPT to specific search engines. They're proxied through OpenAI's purpose-built infrastructure.
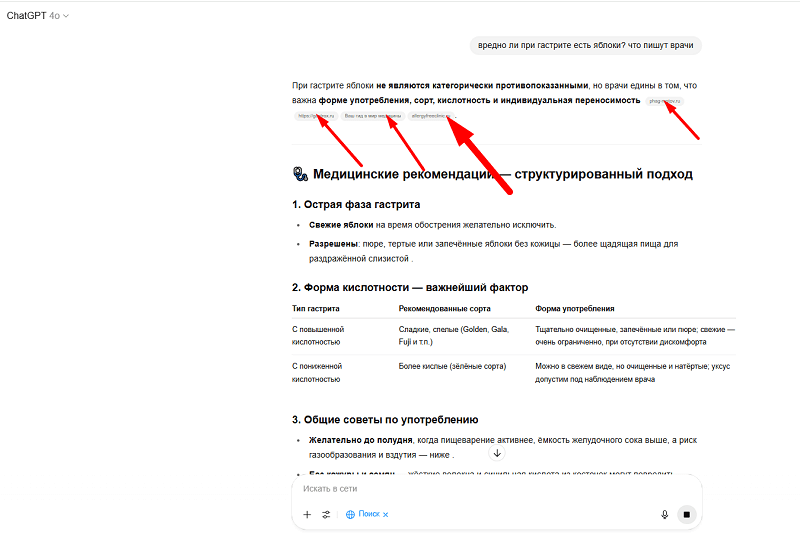
Sometimes the answer doesn't surface any data sources. That tends to happen with fairly simple answers.

So, a search is triggered when the content topic:
- is missing from the AI's knowledge base for any reason;
- is sufficiently local;
- requires up-to-date data.
How does GPT build a search query?
By default, the main query text is in English. Why? Because it gives maximum coverage of relevant and primary sources (documentation, official blogs, international media). And search engine algorithms (Google in particular) rank English-language results more accurately for technical, professional, and educational topics.
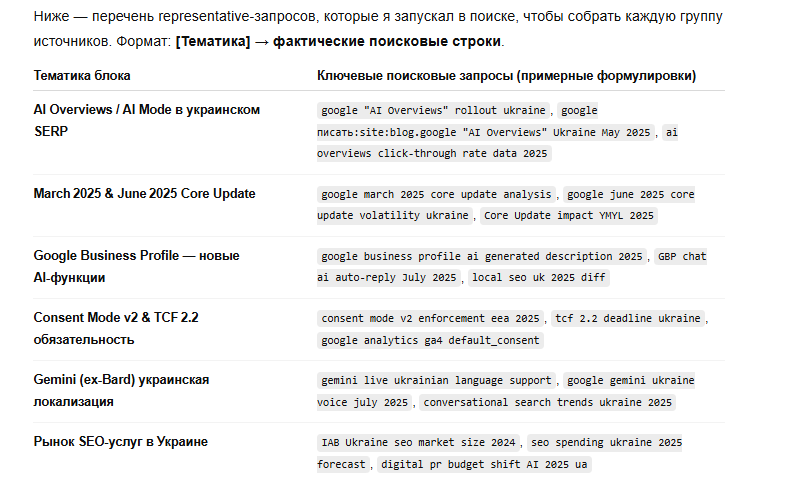
But a local language is also possible (Ukrainian, Polish, etc.) when the question concerns local legislation, news, cases, or local tools.
The second reason is when the content you're after is mostly created in a local language (niche industries, regional markets). I ran queries to see by what scheme it would search for news in Odesa, and here's what it told me.

You can practice this yourself by setting up a prompt like this:
<Your prompt here, for example what's the news in Odesa today
and then, after that, output the text of the search queries you sent to the OpenAI search backbone>
A hybrid approach is also common. Two parallel queries are formed — one in English and one in the local language. Then the SERPs are compared by content structure and depth.
The search query is built on the principle of semantic relevance and user intent (search intent). The main emphasis is on precisely formulating the task.
The query-building algorithm looks like this:
- Term normalization: eliminating homonyms, using industry synonyms.
- Entity refinement: adding specific attributes — geolocation, time frames, industry terms.
- Query type:
- informational (how, what, why, guide, comparison);
- navigational (official sites, regulations, specifications);
- transactional (API access, downloads, tools, templates).
- Quality modifiers:
- site:gov, filetype:pdf, intitle:, inurl: — to narrow the selection by format and source.
- negative operators -example, -reddit — to cut out irrelevant noise.
The general query schema looks like this:
[main entity] + [refinement / modifiers] + [filters / operators]
| Component | Purpose | Examples |
| Main entity | The core of the query (topic, object, error) | E-E-A-T, canonical, 301 redirect, CTR model |
| Refinement | Action, question, or characteristic | update, best practice, comparison, seo impact |
| Modifiers | Refining context, result type, format | checklist, guide, whitepaper, case study, vs |
| Filtering operators | Limiting sources or the time interval | site:, OR, intitle:, filetype:, after: |
| Negation (if needed) | Excluding unnecessary or irrelevant content | -reddit, -quora, -forum, -opinion |
I asked it to spell out some examples, and here's what it gave me:
If you need to find the latest changes in Google's E-E-A-T algorithm, the system will build a query like:
google E-E-A-T update site:developers.google.com OR site:searchenginejournal.com after:2024-01-01
If I asked it whether to choose Canonical or Noindex, it would search like this:
canonical tag vs noindex site:moz.com OR site:developers.google.com after:2023-01-01
In other words, it uses the advanced search logic I wrote about in the article "Google Search Secrets"
Why does GPT search a specific site (site:)? It decides to when a topic meets these three criteria:
- It needs to get the official position (for example, Google, Meta, Microsoft).
- The site contains expert or structured material that's easier to filter within its own content.
- It needs to bypass external interpretations and SEO noise.
But most often we're interested in the second variant — when it searches across the whole internet.
And that kicks in in three cases:
- The topic is niche, little-known, or new — and it's unclear who has covered it.
- A diversity of viewpoints is needed (opinions, cases, comparisons).
- It's important to assess the information noise and the level of competition for the query.
Where does the query happen?

The most interesting part is that GPT doesn't use a single search engine. Few people talk about this, but the fact remains: the query isn't sent directly to a search engine — it goes to the OpenAI search backbone.
It:
- Pulls results from one or several aggregated sources (including Google, Bing, DuckDuckGo, and others).
- Selects 3 to 10 results per query.
- Removes irrelevant or potentially unsafe pages.
- Prioritizes official, authoritative sources (gov sites, leading media, etc.).
And here's the nuance — to make our content rank under this same query-building logic and land in the TOP 10 of the search engines listed below.
| Search engine / Resource | Purpose |
| The main universal source | |
| Bing | Alternative source, resilient to geo-blocking |
| DuckDuckGo | Quick checks, minimizing cached noise |
| Google Scholar | For academic and patent publications |
| You.com / Neeva (if available) | Contextualized search, minimizing SEO noise |
| Niche sites (StackOverflow, Reddit, GitHub, SEJ) | Industry expertise |
A specific subset gets filtered out of the results for such queries:
- Top 5 results — mandatory analysis. Getting your content into the TOP 5 is our goal.
- Positions 6–10 — if the query is rare, niche, or requires alternative viewpoints. This applies when it's genuinely hard to find anything in the results.
- Positions >10 — analyzed only when there's a clear shortage of relevant content (long-tail queries). This almost never happens with ordinary queries.
How are search results selected?
This is the point where link builders should pay attention. And so should content creators.
Priority for "studying" the material goes to the following types of sites.
- Official domains — *.gov, *.edu, *.org, sites of developer companies and standards bodies (W3C, ISO, IETF).
- Specialized media — Search Engine Land, Moz, Ahrefs, SEMrush, SEJ (if we take my niche).
- Forums / StackOverflow / GitHub — for technical questions.
- Topical blogs — only with cross-validation against primary sources.
Having your own authored content on platforms like these is a must-have.
But what do you do if the topic in this area hasn't been covered?
What matters for content quality in GPT?
Of course, the jokes among SEO specialists about where GPT pulls its answers from have been around for a while. Pages from low-quality content farms ranking for local audiences are no longer the norm — they're a nightmare.
But if you specify the country in the query, then yes — it will try to pick out sites from that particular country.
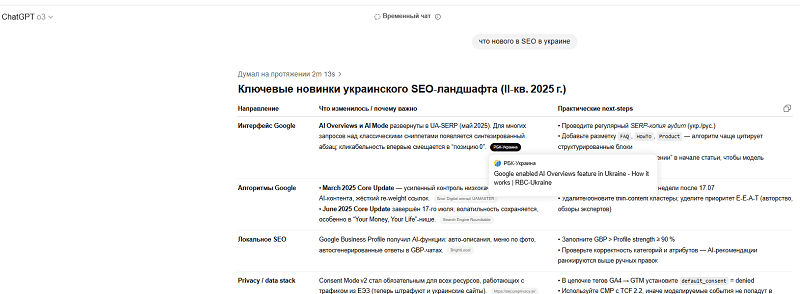
I asked GPT what logic it uses to "filter" results, and here's what I found out.
- Publication date — no older than 12 months for technology topics.
- Authorship — there needs to be an expert's name spelled out or an organization specified (in the Schema.org markup).
- High domain authority (yes, it has a metrics database it checks against).
- Structure and metadata — basics here: a clearly defined H1, an H2-H3 hierarchy, with tables and quotes being welcome.
- Outbound links to official sources. Yes, the very ones nobody likes to add on their own site.
How does GPT interpret the results it finds?
If you thought it found your URL and that's that — I'll disappoint you. The first thing it does is analyze the snippet: if it precisely answers the query, that site will be opened.
An important note. OpenAI and similar LLM systems don't "see" snippets directly from Google in real time.
The query is routed to a search engine (for example, Bing or the Google Custom Search API). Then a JSON is returned with the fields:
- title
- snippet or description
- url
So getting these right can already guarantee your URL makes it into its answer — if your metadata and even your URL (clean, readable slug) reflect:
- the completeness of the answer,
- the match to the question,
- uniqueness / repeatability among the other fragments in the results.
The model reads that exact fragment (the snippet) as the primary source of first contact with the information.
You can write and check your metadata in our tool Unmiss Website Audit, where you can preview the snippet and edit your metadata.
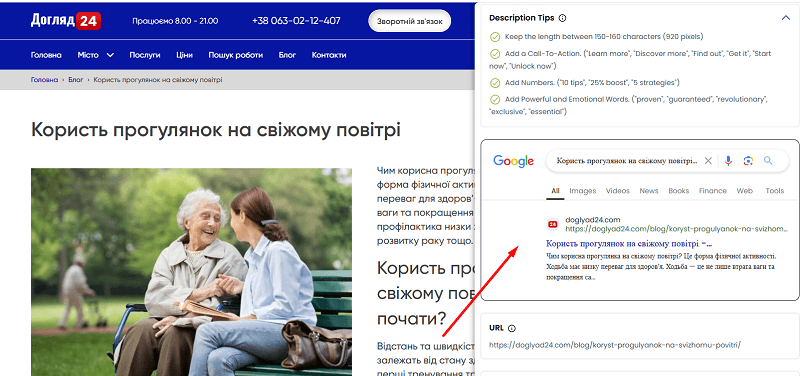
An interesting fact. If the snippet contains a highly relevant and complete answer, the model will more likely skip that URL as already "handled" — it won't open it — and will simply count it as the answer. But if the snippet is partially relevant yet contains incompleteness, a question, or something left unsaid, the model will very likely open the site to read on and "understand it fully."
Make your snippet relevant enough, but leave a knowledge gap in it, especially for complex or expert topics.
Then comes the semantic parsing of the content and data. The system is able to aggregate data from several sources to synthesize information. In the end, if the info is outdated or contradictory, it gets flagged as "requires confirmation" and the data is ignored in the analysis.
Semantic parsing isn't just text analysis — it's multi-level intelligent processing of information aimed at:
- obtaining reliable, verified facts;
- building a coherent picture from fragments across heterogeneous sources;
- ensuring flexibility and adaptability in automated decision-making (for example, in recommendation systems or trend analytics).
Let's break down how the parsing of content and data actually happens:
- First, the content is stripped of markup, HTML tags, JS, and non-informational noise.
- Then lemmatization is performed, stop words are removed, and everything is brought to a single format (dates, numbers, units of measurement).
For this, technologies like Named Entity Recognition (NER), Part-of-Speech Tagging (POS), Dependency Parsing, and Semantic Role Labeling (SRL) are applied.
Why are they needed? To identify key entities — names, companies, products, categories — to build relationships between objects (who did what, when, and with what result), and to recognize tone, context, and the level of credibility.
How to pick a topic for GPT answers?
Given everything above, you'll need to master the logic of building queries in your niche. It's hard, but overall it just takes a bit of time. The task is to gather all the query long tails and try to "generate" search-engine queries from them.
- Check the top 5 SERP for your key query: are there unanswered questions, outdated data, or a missing local angle?
- Look for topics where GPT is forced into a web search (a knowledge gap after June 2024).
I recommend getting comfortable with our simple query generator tool.
Examples of such queries could be:
- High-intent long-tail: "how to choose {product} 2025," "steps to implement {technology} in Ukraine." This also always includes new releases, changes to standards, and local cases — things that haven't settled into the LLM's knowledge base. These will always be "googled."
- For ready-made keywords, we simply check them in the results and see what's there. In the future, I'll improve the tool so this can be done in a couple of clicks.
Look at whether the content exists. If it does — skip those queries. If it doesn't, or it's junk — that's our topic for a piece.
A reminder: we add queries using the hybrid method — in English and in the local language. Formulate both the English and the local-language version of the key phrase; make sure both reflect the same entity.
Next, structure the topic right away around future subheadings. Use a micro-outline (H2-H3-H4) before you even start writing, and aim for each H2 to answer a specific sub-intent (guide, comparison, roundup, checklist). Any mind-map service works great for this.
Next we move on to metadata. And here our title calculator will help.
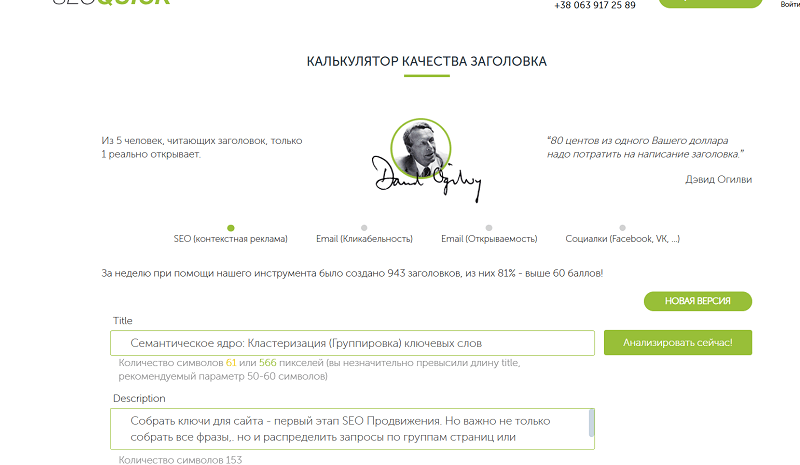
- Title — include the main entity + a refinement of the action/value + the year, if relevant. Try to keep the length to 61 characters.
- Description — briefly answer the intent and leave something "unsaid" so the LLM clicks through to the site.
- H1 — restate the topic, but without templated words like "Guide" or "Overview." That is, just the main keyword.
Other things that absolutely must be present on the page:
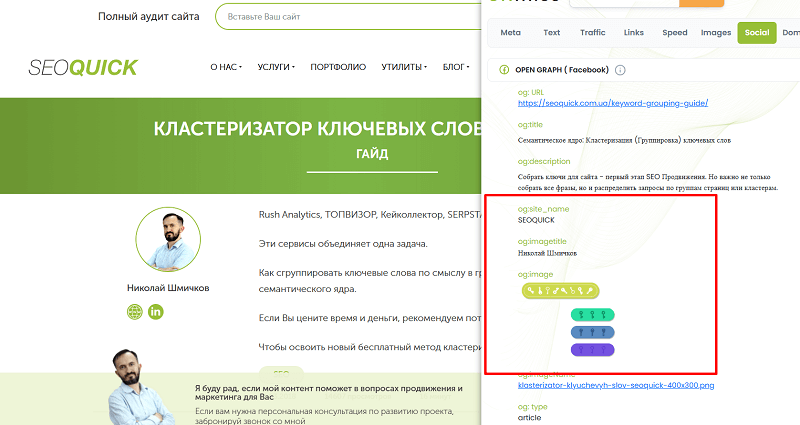
- OG tags / Twitter Cards — duplicate the Title + an emotional call, and add a relevant 1200×630 px image.
- Schema.org Article — be sure to specify author, datePublished, headline, publisher.logo.
- OG markup for the author and other elements.
We also try to keep the URL as simple as possible — short, no stop words, Latin characters, hyphen separators. Remember semantic predictability: let the URL make it immediately clear what the AI backbone will find here, and avoid amorphous things like /blog/post-123.
What about the year? For annual topics, use /topic-2025/. Don't forget to set up a 301 redirect from the old /topic-2024/ afterward. For evergreen material — no year, with an update date in Schema.org. And don't forget to refresh the material every year.
As for URL nesting depth — a maximum of 3 levels. That is, folder, subfolder, page. There's no need to deepen the URL structure beyond that.
/seo/technical/canonical-vs-noindex
A logical hierarchy helps the LLM understand the "parent > child material" context.
It's also important that the locale is accounted for here — a language prefix like /uk/, /ru/, or a subdomain like uk.example.com — so GPT picks the right locale during the query.
By following this scheme, you maximize your chances of landing in those 3–10 results that the GPT backbone actually reviews, rather than just showing in the snippet.
How content gets into AI Overviews and Perplexity in 2026
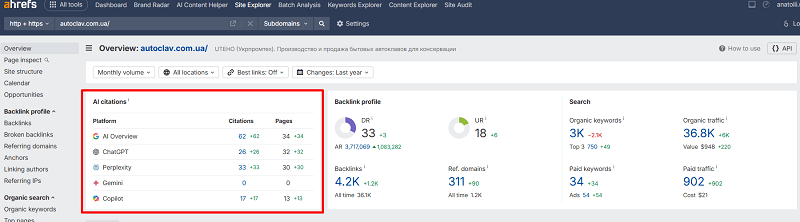
The GPT backbone's logic is only half the picture. In 2026, the main flow of AI traffic comes through Google AI Overviews and Perplexity, and the rules here are a little different. The key shift: landing in the organic TOP 10 no longer guarantees a citation. According to an Ahrefs study, the share of AI Overviews citations from TOP 10 pages dropped from 76% (mid-2025) to 38% by early 2026 — the rest comes from pages ranked 11–100 and even deeper. The reason is query fan-out: Google breaks your query into dozens of subqueries and cites the pages that surface most often across that whole fan, not just for the main keyword. That's why it's important to cover not a single intent but the entire cluster of related questions on one page — exactly the hybrid-query and micro-outline logic we discussed above. We go deeper into the mechanics in our piece on GEO optimization for GPT.
Perplexity works differently: every answer by default contains numbered links to sources, and the platform is extremely sensitive to freshness and authority. According to an analysis of 366,000+ citations (a study by Kai-Cheng Yang, 2025), about half of Perplexity's links lead to 2025 material, and ~80% point to content from the last 2–3 years; high-authority domains receive up to 40% more citations than ordinary blogs. At the same time, the overlap of sources between platforms is minimal — around 11% of domains are cited in both ChatGPT and Perplexity at once — so you should bet on universal signals: a clear structure with a direct answer in the first 30% of the page, regular date updates, expert authorship in Schema.org, and fact-checking against external sources. We've gathered a ready-made set of formulations for testing your pages against different models in our collection of 50 mega-prompts for ChatGPT and Gemini for SEO.
Results
With a proper level of content quality and correctly written metadata, your sites will grow and keep delivering results in AI answers — always.
Regardless of the niche, whether it's manufacturing, medicine, or anything else.
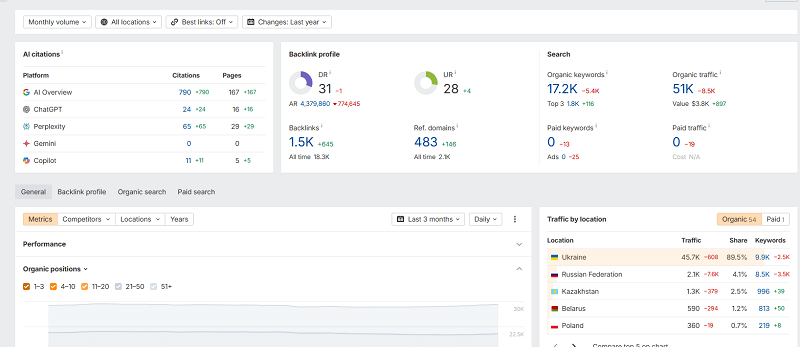
In the medical niche, with proper content quality and semantic work on the pages, you can achieve genuinely huge results with minimal effort — because you don't need links from marketplaces or crowd marketing for it, just meticulous work on content and the right PR.

SEO Services for AI Promotion
If you'd like to order SEO services for promotion in AI, fill out this form and book a consultation — we'll discuss a strategy with you for creating content that AI loves.

Broken Links and Redirect Chains: Clearing 3XX, 4XX and 5XX Without Bleeding Link Equity
Broken links and extra redirects quietly steal traffic, crawl budget and link equity — and they push your pages out of AI answers. Here's what actually goes wrong and how to get your hops down to zero.
Read →
Merchant Center for AI Mode: Getting Your Product Feed Ready for Conversational Shopping in 2026
Google AI Mode is reshaping product search and a plain feed no longer cuts it. Here are the new Merchant Center attributes, why stores get banned, and where to start.
Read →
Image SEO Optimization: alt, Dimensions and Weight for Core Web Vitals
How to optimize images for SEO in 2026: why alt text matters, how width and height stop layout shifts (CLS), which formats (WebP, AVIF) to use, and how not to break LCP with lazy loading. A guide from SEOquick.
Read →Want to apply this to your site?
We will review the current situation, find the first growth levers, and suggest a practical working format.
