Duplicate Content: The Silent Traffic Killer — How to Find and Fix It
Google won't hand you a penalty for duplicate content — but it's exactly what quietly eats your traffic. Here's what counts as a duplicate, why duplicates dilute your signals and hurt AI search, and how to find and fix them with Search Console and Screaming Frog.
Google doesn't penalize your site for duplicate content — but that doesn't make it harmless. Duplicates dilute link signals, waste crawl budget, and make it harder for AI search engines to identify you as the source. Google estimates that as much as 25–30% of all web content is duplicate, and it's almost always a technical mistake rather than intent.
The SEO community is still confused about duplicate content: some warn of a "ban," others wave it off, assuming Google will sort it out. The truth is in between — and it matters more than it looks. Below I break the topic down based on a video from our SEOquick channel: what counts as a duplicate, why it kills organic traffic, and how to find and fix it — with numbers and sources.

What Counts as Duplicate Content
In Google's eyes there are just four types of duplicates, and each is fixed differently:
1. Internal technical duplicates. Identical content on different URLs within one site: parameterized pages (?utm=, filters, sorting, ?page=), empty templated pages with no metadata, pagination, blog tags and categories the CMS generates automatically.
2. Hosting duplicates. Server misconfigurations: no redirect from HTTP to HTTPS, or from www to non-www. The result is fully identical versions of your site living on different protocols and subdomains.
3. Your own external duplicates. Your content that you spread across several domains yourself — for example, the same press release or description on different projects.
4. Third-party external duplicates. Copies of your content on other domains without your knowledge: RSS scraping, press-release reposts, rewrites, and outright theft.

Does Google Penalize Duplicate Content?
Short answer: no, there is no separate duplicate-content penalty. Google's John Mueller has said repeatedly that a site isn't punished for duplicate content — the search engine simply clusters similar pages, picks one to show, and hides the rest. Google's documentation confirms it: the system consolidates duplicates and chooses a canonical URL on its own.
The downside is you never learn which page Google hid, or why. And here's the key nuance Nikolay frames in the video:
"It looks like Google itself isn't hurting you — but its algorithm's scoring of your site is. And every duplicate page that lands in the index because of your mistake lowers the overall rating of your resource."
So formally no "minus" is added to the site, but its total weight gets diluted across dozens of junk pages. Mass-copied external content is its own story: it lowers the perceived quality of the site and its ability to rank for competitive queries. The takeaway is simple: duplicates are a serious technical error that hits your rankings strategically.
Why Duplicates Quietly Kill Organic Traffic
Duplicates don't crash a site all at once — they do it invisibly, in three ways:
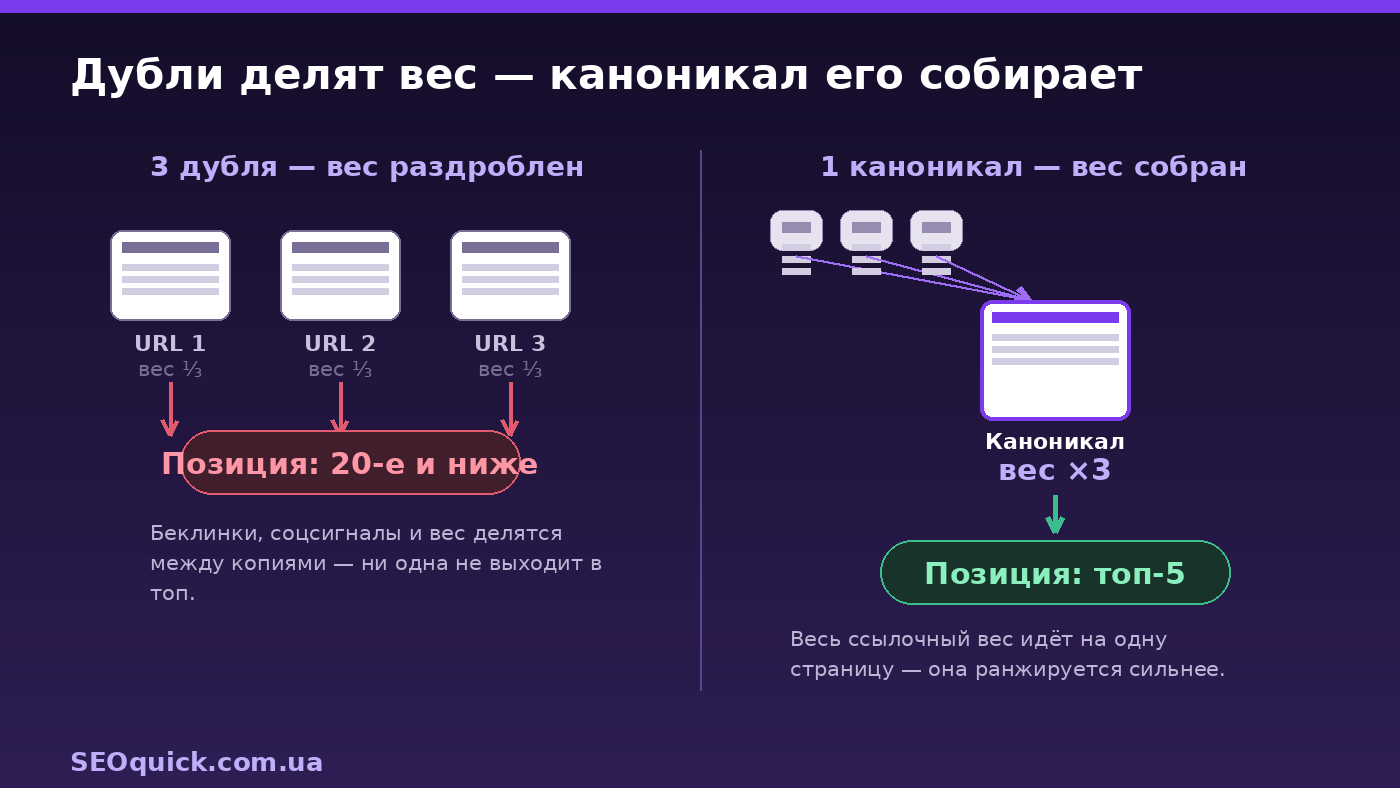
Signal dilution. When the same material is reachable via several URLs, the search engine splits ranking signals across the versions instead of consolidating them into one strong page. Backlinks to different duplicates don't combine their authority, and social shares scatter across copies. According to industry estimates, sites with notable duplicate issues lose 15–20% of organic traffic compared to similar sites with proper canonicalization.
Crawl budget. The bot spends crawls on useless copies instead of your real pages — new content gets indexed slower.
Invisibility to AI search. This is the new, underrated risk of 2026. ChatGPT, Perplexity, and Claude pick an authoritative, unique source when generating answers. When your content is fragmented across several URLs, the AI system can't clearly identify you as the origin — and cites a competitor instead. For how to get into AI answers in the first place, see our guide on GEO optimization for GPT.
How to Find Duplicates: 3 Working Methods
1. Search operators. The fastest way to gauge the scale. Use site:yourdomain inurl:page to find pagination pages in the index, and site:yourdomain intitle:"title fragment" to find pages with identical titles. This is often how junk versions on a stray subdomain surface.
2. Screaming Frog (or an alternative). The Content → Near Duplicates report shows pages with high content similarity. Unlike a grammar check, this report doesn't lie: it genuinely finds pages where content is too thin or nearly repeated. And thin content is a common reason pages rank poorly.
3. Google Search Console. The most honest source. Go to "Page indexing" → the "Why pages aren't indexed" block. Watch two statuses:
— "Duplicate without user-selected canonical" — Google decided the page is a duplicate and you didn't specify a canonical.
— "Duplicate, Google chose different canonical than user" — you set a canonical, but Google disagreed (see Google's troubleshooting guide). Most of the time Google is right — recheck your canonicalization logic.
How to Fix Duplicate Content
Once the duplicates are found, resolve them by type:
301 redirects. For hosting duplicates, this is the only correct path: HTTP → HTTPS, www → non-www, all mirrors to one version. Point internal links only at the canonical version, and add only that one to Search Console.
Canonical. Add a self-referencing canonical to every page (even pointing to itself) and a cross-domain canonical if you legally republish someone else's material. Important: don't specify different canonical URLs via different methods (one in the sitemap, another in rel=canonical) — Google will get confused. For syndication, Google recommends blocking indexing of the copy on the partner's side rather than a canonical.
Hreflang for language versions. Our site is bilingual (RU/UA), and without hreflang, versions in similar languages can be treated as duplicates. In the <head> you declare the primary language and the alternates plus x-default. More in our piece on technical SEO for Ukrainian sites.
Robots and junk removal. Block parameterized pages (UTM tags, filters) with rules in robots.txt; delete technical pages that shouldn't exist at all — and disable the ability to generate them.
Dev versions — behind a password. A classic failure is a staging version left in the index. Here Nikolay is blunt:
"Lock your dev version behind a login and password, and nothing else. Noindex on the page won't save you either, I guarantee it."
DMCA against theft. If your original content is being stolen, set up DMCA protection: the service works directly with Google on copyright violations. Also publish first — that way Google records you as the source.
Frequently Asked Questions About Duplicate Content
Does Google penalize duplicate content?
No, there is no separate penalty. Google clusters similar pages and shows one. But duplicates dilute signals and crawl budget, which makes the site rank worse.
How many duplicates is a problem?
It's not about the count — it's that duplicates get indexed and compete with each other. Even a few parameterized copies of an important page already split its weight.
Canonical or 301 — which to choose?
If the duplicate URL isn't needed by users — a 301 redirect (a strong signal). If the page is needed (e.g., a filtered version) but shouldn't rank — a canonical to the main page.
Do duplicates affect getting into AI answers?
Yes. Content fragmented across URLs makes it harder for ChatGPT, Perplexity, and Claude to identify you as the origin, reducing your chance of being cited.
Duplicate content isn't about a "Google ban" — it's about a slow traffic leak that's easy to miss. Find duplicates with Search Console and Screaming Frog, consolidate them with redirects and canonicals, and your site's weight gathers where it actually works. If you'd like your site checked for duplicates, send us your site's address — we'll do a free audit.

Agentic SEO in 2026: How AI Agents Do SEO Tasks for You
What agentic SEO is and which tasks AI agents already handle themselves: research, optimization, monitoring. Real examples, 2026 numbers and Gartner's warning — a breakdown from SEOquick.
Read →
AI Content and Google in 2026: What Actually Gets Penalized (Spoiler — Not AI)
Google does not penalize text for being written by AI — that is the official position. Here's what scaled content abuse really is, what changed after the 2026 updates, and how to publish AI content that still ranks.
Read →
Best AI SEO Tools in 2026: A Roundup by Task and Price
A 2026 roundup of the best AI SEO tools by task and price: Ahrefs, Semrush, Surfer SEO, ChatGPT, Claude, Profound, Otterly. Which stack to assemble for your budget — a breakdown from SEOquick.
Read →Want to apply this to your site?
We will review the current situation, find the first growth levers, and suggest a practical working format.