Дублі контенту: тихий вбивця трафіку — як знаходити та усувати
Google не видає штраф за дублі контенту — але саме вони тихо з'їдають ваш трафік. Розбираю, які бувають дублі, чому вони розмивають сигнали й заважають AI-пошуковикам, і як знаходити та усувати їх через Search Console і Screaming Frog.
Google не штрафує сайт за дублі контенту — але це не означає, що вони безпечні. Дублі розмивають посилальні сигнали, з'їдають краулінговий бюджет і заважають AI-пошуковикам визначити вас як джерело. За оцінкою Google, до 25–30% усього контенту в мережі — дублікати, і майже завжди це технічна помилка, а не злий намір.
Навколо дублюючого контенту в SEO-спільноті досі плутанина: одні лякають «баном», інші махають рукою — мовляв, Google сам розбереться. Правда посередині, і вона важливіша, ніж здається. Нижче розбираю тему за відео з нашого каналу SEOquick: що вважається дублем, чому він убиває органіку і як його знаходити та усувати — з цифрами й джерелами.

Що вважається дублем контенту
Очима Google дублів усього чотири види, і лікуються вони по-різному:
1. Технічні внутрішні дублі. Однаковий контент на різних URL усередині одного сайту: сторінки з параметрами (?utm=, фільтри, сортування, ?page=), порожні шаблонні сторінки без метаданих, пагінація, теги й категорії блогу, які рушій генерує автоматично.
2. Хостинг-дублі. Помилки конфігурації сервера: немає редиректу з HTTP на HTTPS або з www на без-www. У підсумку у вас існують повністю ідентичні версії сайту на різних протоколах і піддоменах.
3. Власні зовнішні дублі. Ваш контент, який ви самі розклали по кількох доменах — наприклад, один і той самий пресреліз або опис на різних проєктах.
4. Зовнішні дублі від третіх осіб. Копії вашого контенту на чужих доменах без вашого відома: RSS-парсинг, репости пресрелізів, рерайти й відверте крадійство.

Чи штрафує Google за дублі контенту?
Коротка відповідь: ні, окремого штрафу за дублі не існує. Джон Мюллер з Google не раз повторював: сайт не карається за дублюючий контент — пошуковик просто кластеризує схожі сторінки й обирає одну для показу, а решту не показує. Це підтверджує й документація Google: система склеює дублі й обирає канонічний URL сама.
Мінус у тому, що ви не дізнаєтеся, яку сторінку Google приховав і чому. І тут ключовий нюанс, який на відео формулює Микола:
«Начебто сам Google вам не шкодить, але його система розрахунку алгоритму для вашого сайту шкодить. І кожна дублююча сторінка, яка потрапляє в індекс через вашу помилку, загалом знижує рейтинг вашого ресурсу».
Тобто формально «мінуса» до сайту не додають, але сумарна вага сайту розмивається по десятках сміттєвих сторінок. Окрема історія — масово скопійований зовнішній контент: він знижує сприймальну якість сайту й ранжованість за конкурентними запитами. Висновок простий: дублі — це серйозна технічна помилка, яка б'є по просуванню стратегічно.
Чому дублі тихо вбивають органіку
Дублі не роняють сайт одномоментно — вони роблять це непомітно, за трьома напрямами:
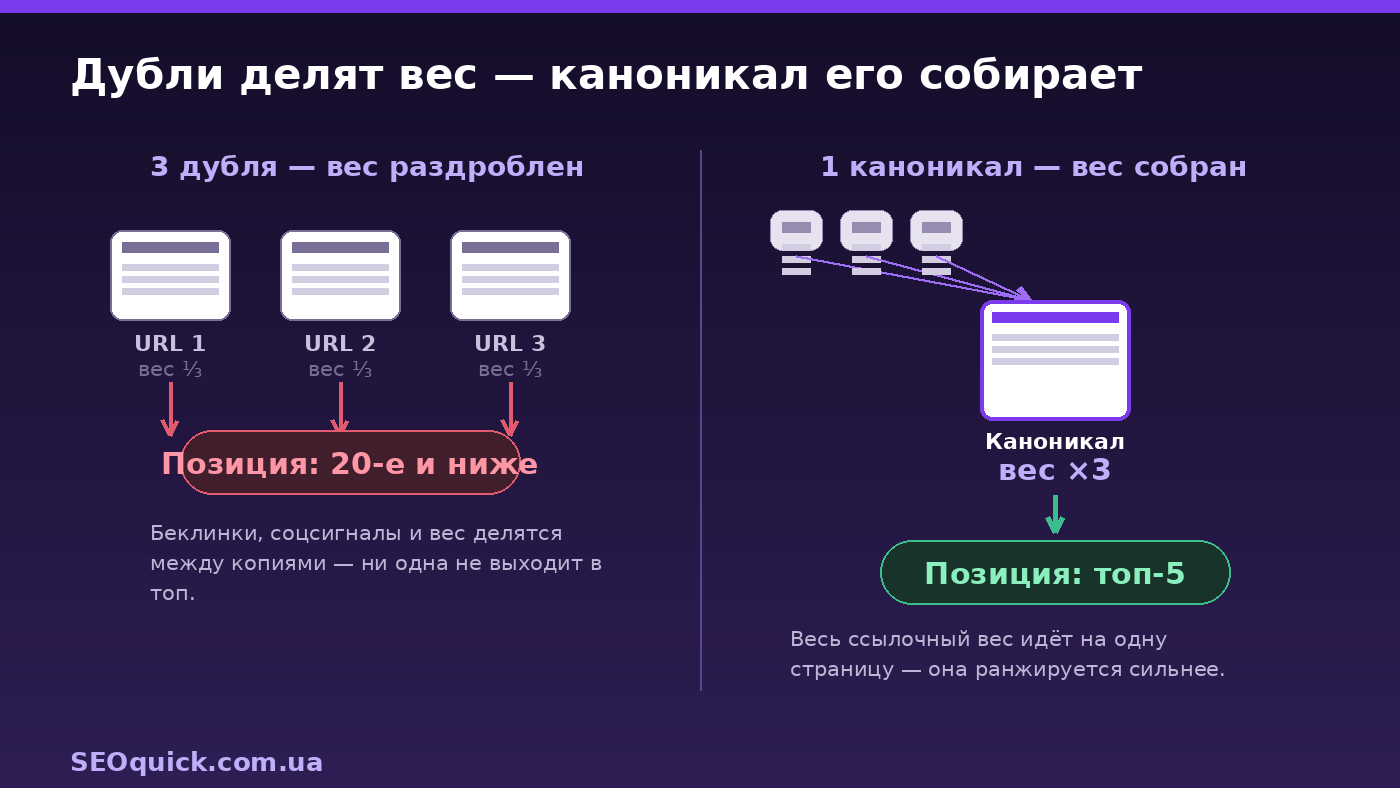
Розмивання сигналів. Коли один і той самий матеріал доступний за кількома URL, пошуковик розподіляє ранжувальні сигнали між версіями замість того, щоб зібрати їх в одну сильну сторінку. Беклінки на різні дублі не сумують авторитет, а поширення в соцмережах розсіюються по копіях. За даними галузевих оцінок, сайти з помітними проблемами дублів втрачають до 15–20% органічного трафіку відносно схожих сайтів із коректною канонізацією.
Краулінговий бюджет. Робот витрачає обходи на марні копії замість ваших робочих сторінок — нові матеріали індексуються повільніше.
Невидимість для AI-пошуку. Це новий і недооцінений ризик 2026 року. ChatGPT, Perplexity і Claude під час генерації відповідей обирають авторитетне, унікальне джерело. Коли ваш контент фрагментований по кількох URL, AI-система не може однозначно визначити вас як першоджерело — і цитує конкурента. Про те, як загалом потрапляти в AI-відповіді, ми писали в гайді з GEO-оптимізації сайту під GPT.
Як знаходити дублі: 3 робочі способи
1. Пошукові оператори. Найшвидший спосіб прикинути масштаб. Через site:вашдомен inurl:page знайдете сторінки пагінації в індексі, через site:вашдомен intitle:"фрагмент заголовка" — сторінки з однаковими тайтлами. Часто саме так спливають сміттєві версії на чужому піддомені.
2. Screaming Frog (або аналог). У звіті Content → Near Duplicates інструмент показує сторінки з високою схожістю контенту. На відміну від перевірки граматики, цей звіт не бреше: він реально знаходить сторінки, де контенту замало або він майже повторюється. А мало контенту — це і є часта причина, чому сторінки погано ранжуються.
3. Google Search Console. Найчесніше джерело. Розділ «Індексування сторінок» → блок «Чому сторінки не індексуються». Дивимося два статуси:
— «Сторінка є копією. Канонічний варіант не обрано користувачем» — Google вважав сторінку дублем, а ви не вказали canonical.
— «Сторінка є копією. Google обрав канонічною іншу сторінку, ніж вказано користувачем» — ви прописали canonical, але Google з вами не погодився (див. гайд Google з усунення). Найчастіше Google має рацію — варто перевірити логіку канонізації.
Як усувати дублі контенту
Після того як дублі знайдено, вирішуємо за типами:
301-редиректи. Для хостинг-дублів — єдиний правильний шлях: HTTP → HTTPS, www → без-www, усі дзеркала на одну версію. Внутрішні посилання проставляємо тільки на канонічний варіант, у Search Console додаємо тільки його.
Canonical. Ставте self-referencing canonical на кожну сторінку (навіть на саму себе) і cross-domain canonical, якщо легально републікуєте чужий матеріал. Важливо: не вказуйте різні канонічні URL різними методами (один у sitemap, інший у rel=canonical) — Google заплутається. Для синдикації Google рекомендує не canonical, а заборону індексації копії в партнера.
Hreflang для мовних версій. Наш сайт двомовний (RU/UA), і без hreflang версії схожими мовами Google може вважати дублями. У <head> прописується основна мова й альтернативні плюс x-default. Детальніше — у матеріалі про технічний SEO для українських сайтів.
Robots і видалення сміття. Параметричні сторінки (UTM-мітки, фільтри) закривайте правилами в robots.txt; технічні сторінки, які взагалі не мають існувати, — видаляйте й вимикайте саму можливість їх генерації.
Dev-версії — на пароль. Класичний провал — забута в індексі тестова версія сайту. Тут Микола категоричний:
«Закривайте Dev-версію винятково на логін-пароль. Noindex сторінці теж вам не допоможе, я вам гарантую».
DMCA проти крадійства. Якщо ваш авторський контент крадуть, підключіть DMCA-захист: сервіс напряму працює з Google щодо порушення авторських прав. Плюс публікуйте матеріали першими — так Google зафіксує джерелом саме вас.
Часті запитання про дублі контенту
Чи штрафує Google за дублі контенту?
Ні, окремого штрафу немає. Google кластеризує схожі сторінки й показує одну. Але дублі розмивають сигнали й краулінговий бюджет, через що сайт ранжується гірше.
Скільки дублів — це вже проблема?
Проблема не в кількості, а в тому, що дублі потрапляють в індекс і конкурують між собою. Навіть кілька параметричних копій важливої сторінки вже дроблять її вагу.
Canonical чи 301 — що обрати?
Якщо дублюючий URL не потрібен користувачу — 301-редирект (сильний сигнал). Якщо сторінка потрібна (наприклад, версія з фільтром), але не має ранжуватися — canonical на основну.
Чи впливають дублі на потрапляння в AI-відповіді?
Так. Фрагментований по різних URL контент заважає ChatGPT, Perplexity і Claude визначити вас першоджерелом, знижуючи шанс цитування.
Дублі контенту — це не про «бан від Google», а про повільний витік трафіку, який легко не помітити. Знайдіть їх через Search Console і Screaming Frog, склейте редиректами й канонікалами — і вага сайту збереться туди, де вона працює. Якщо хочете перевірити свій сайт на дублі, надішліть нам адресу сайту — зробимо безкоштовний аудит.

Агентний SEO у 2026: як AI-агенти виконують SEO-завдання за вас
Що таке агентний SEO (agentic SEO) і які завдання AI-агенти вже роблять самі: ресерч, оптимізація, моніторинг. Реальні приклади, цифри 2026 і попередження Gartner — розбір від SEOquick.
Читати →
AI-контент і Google у 2026: за що насправді штрафують (спойлер — не за ШІ)
Google не карає текст за те, що його написав ШІ — це офіційна позиція. Розбираю, що таке scaled content abuse, що змінилося після апдейтів 2026 року та як публікувати AI-контент так, щоб він ранжувався.
Читати →
Google AI Mode у 2026: що це і як готувати сайт до розмовного пошуку
Що таке Google AI Mode, чому падає CTR і як потрапляти в його відповіді. Розбір від SEOquick: 1 млрд користувачів, 93% запитів без кліку та робочий чек-лист на 2026 рік.
Читати →Хочете застосувати це до свого сайту?
Розберемо поточну ситуацію, знайдемо перші точки зростання й запропонуємо формат роботи без зайвої теорії.