
AI у SEO завданнях у 2026:Як стати менеджером нейромереж, а не їхнім оператором
Роби SEO разом із нами!

Ще вчора стрічки соцмереж майоріли терміном «Vibe Coding» — концепцією, яку популяризував Андрій Карпати (колишній директор з ІІ в Tesla). Суть її була простою: ти пишеш код «на розслабоні», не дбаючи про синтаксис, а нейромережа підхоплює твій «вайб» і дописує інше. Але індустрія рухається так швидко, що ця концепція вже здається застарілою. Сьогодні ми переходимо до Vibe Working. Це стан, коли ви більше не працюєте з нейромережею, ви працюєте над ними. Ви – диригент оркестру, де кожна модель – це окремий співробітник зі своїм характером, сильними сторонами і, на жаль, галюцинаціями.
У цій статті ми розберемо анатомію сучасного AI-воркфлоу: чому нові моделі брешуть частіше за старі, як змусити їх працювати на бізнес-завдання і чому «паралельний запуск» — це єдиний спосіб вижити у 2026 році.
Першочерговим завданням сьогодні у нас стоїть — саме автоматизація. Ми хочемо, щоб ті речі, за які клієнту доводилося переплачувати, не потрібно було більше цього робити. Наприклад, якісні статті. Журналістські пресрелізи. Але завдяки ШІ сьогодні ми знаємо, що, наприклад, сайт msn.com просто складається зі згенерованих статей. А при пошуку відповідей в ШІ ви бачите посилання — і 50% з них вже згенеровані в ШІ.
І звісно, кожен власник бізнесу хоче зробити так, щоб 10,000 сторінок категорій товарів або 20,000 товарів отримали шикарні описи, сторінки послуг під ключові слова були оптимізовані за день. Але чому досі є бар’єри, і багато хто про них може і здогадується, але ще не стикався. Хто стикався, з вас жирний лайк.
Частина 1. Які проблеми з AI сьогодні
Ейфорія від перших днів ChatGPT минула. На зміну їй прийшов прагматизм і, чесно кажучи, легке роздратування. Якщо ви використовуєте нейромережі для реальної роботи, а не для генерації картинок з котиками, ви напевно зіткнулися з «дитячими хворобами» навіть найбільш просунутих моделей. Я зі свого досвіду вже зіткнувся з тим, що запускаю паралельно кілька нейронок. Одна з них збирає звіт, інша аналізує документ, третя — генерує застосунок, який я буду використовувати надалі.
Нещодавно просто скопіював історію суперечки в чаті, закинув у нейронку і попросив знайти рішення, і о — диво — воно знайшлося.
1. Криза галюцинацій у нових моделях
Головна небезпека ШІ — він ніколи не сумнівається. Він може з абсолютною впевненістю навести вигадану цитату закону або неіснуючу технічну характеристику. Спеціаліст не може «пробігти очима» текст, йому потрібно перевіряти кожен іменник і цифру. Парадокс 2025 року: чим розумніша модель, тим витонченіше вона бреше. Здавалося б, нові reasoning-моделі (ті, що розмірковують) повинні бути точнішими. Але статистика і практика говорять про зворотне.
Зростання галюцинацій у нових моделях
Дані: Бенчмарки 2025 року
- Цифри не брешуть (на відміну від ШІ): Згідно з останнім System Card від OpenAI, їхні новітні моделі o3 та o4-mini демонструють рівень галюцинацій у 33% та 48% відповідно на бенчмарку PersonQA. Для порівняння, попередня ітерація o1 помилялася лише у 16% випадків. (Джерело: TechCrunch, OpenAI System Card Report).
- Чому це відбувається? Дослідники зазначають, що моделі, навчені на ланцюжках міркувань (Chain of Thought), схильні до “over-reasoning”. Замість того щоб просто сказати «я не знаю» або видати факт, модель починає вигадувати правдоподібне обґрунтування, намагаючись “догодити” логіці запиту.
- Зона ризику: Юриспруденція і точні науки. Світ вже бачив кейси (наприклад, справа Mata v. Avianca в США), коли юристи приносили до суду вигадані прецеденти. Якщо ви просите модель знайти статистику для звіту клієнту — перевіряйте кожне число. ШІ може ідеально порахувати конверсію, але вигадати сам факт існування дослідження.
Нейромережі можуть генерувати логічно зв’язний, але фактично невірний контент, що критично в таких темах, як медицина або юриспруденція. Доводиться або перевіряти, або взагалі перегенеровувати все з нуля.
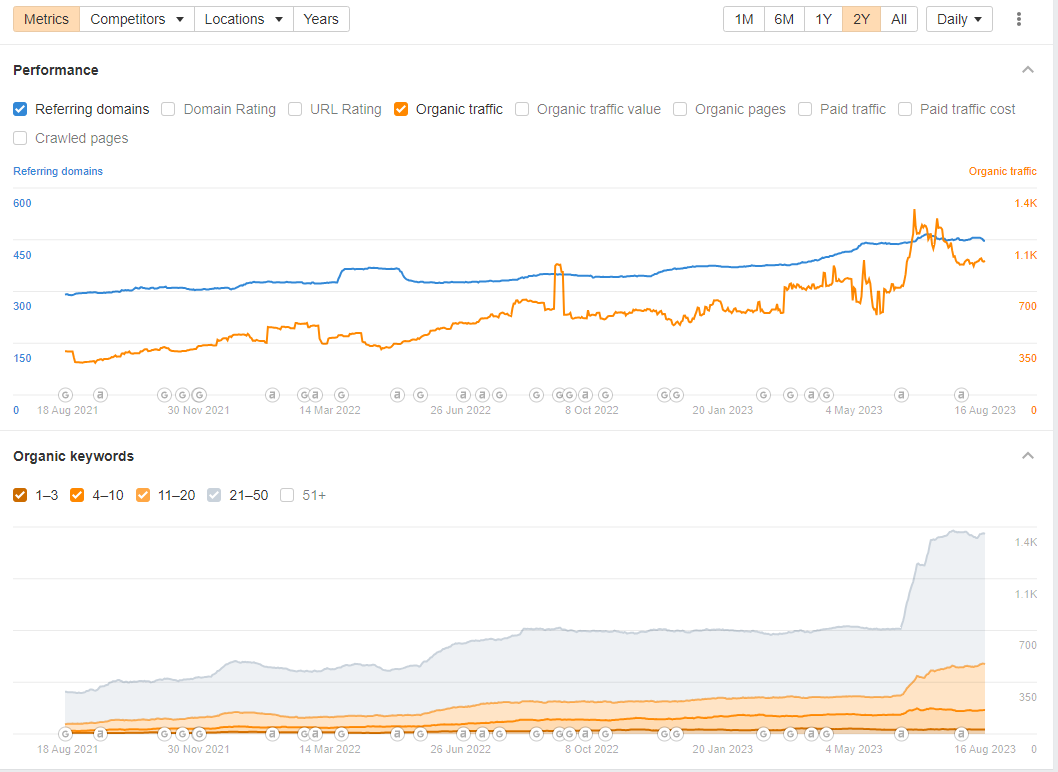
Просування Агентства нерухомості на Кіпрі
- Оптимізація контенту на сайті
- Технічна оптимізація
- Аналіз конкурентів
- Лінкбілдинг
- Налаштування контекстної реклами
- PR просування
- Таргетинг у Facebook та Instagram
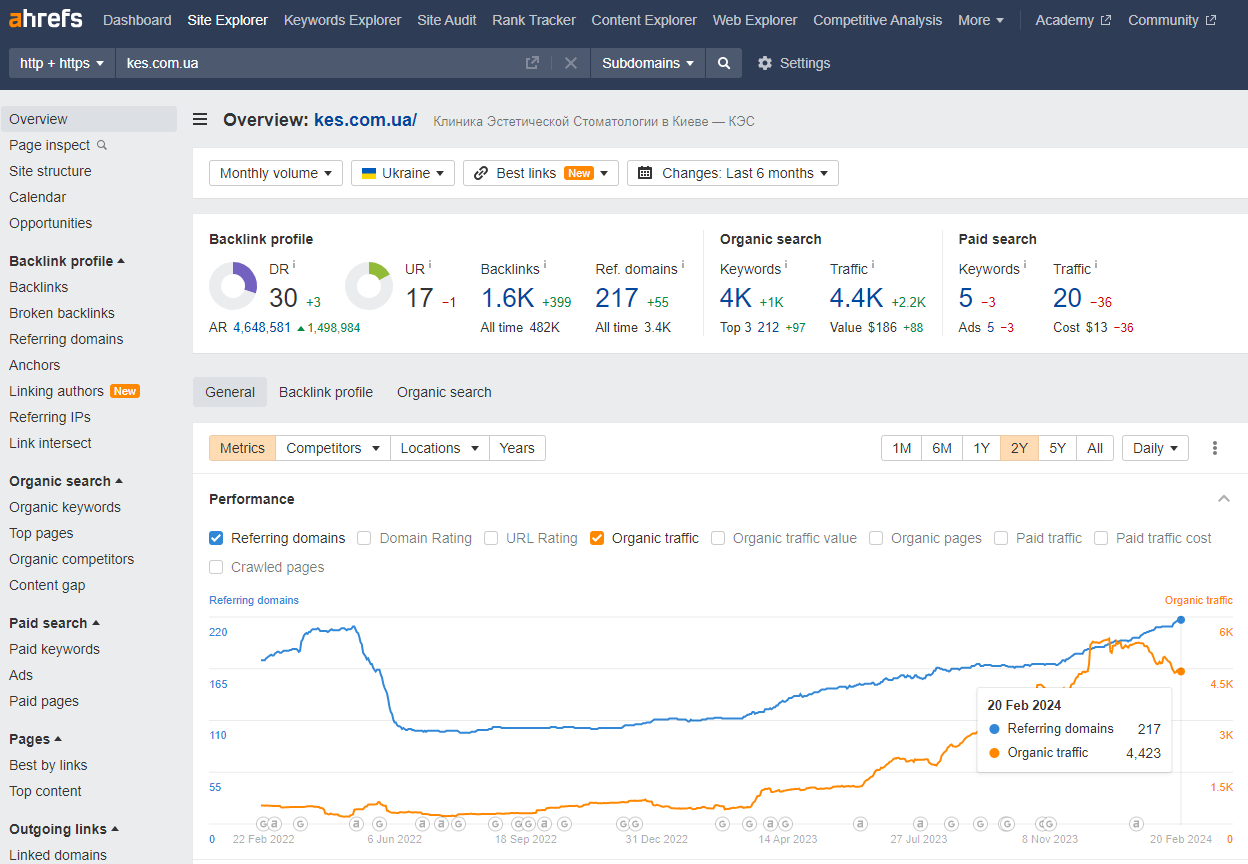
Роботи з розкручування стоматологічної клініки
- Робота за Scholarship
- Аудит сайту за YMYL
- Аудит Юзабіліті
- Технічний аудит
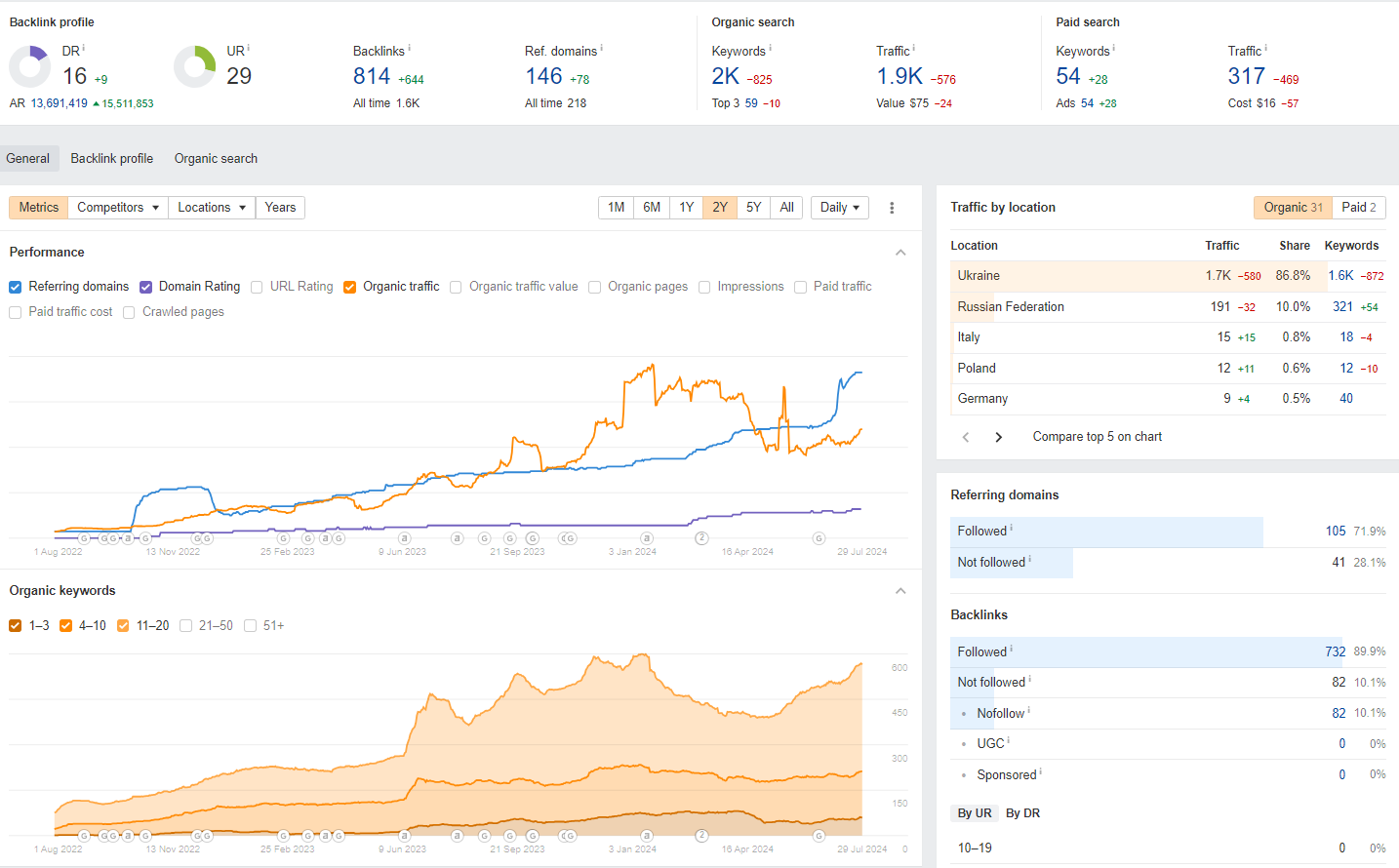
Просування сайту послуг
- Аудит конкурентів
- Аудит контенту + метадані
- ТЗ із переписування слабких сторінок послуг
- Видалення/переписування статей блогу
- Технічний аудит
- Розміщення у довідниках
- Юзабіліті / редизайн
- Scholarship PR
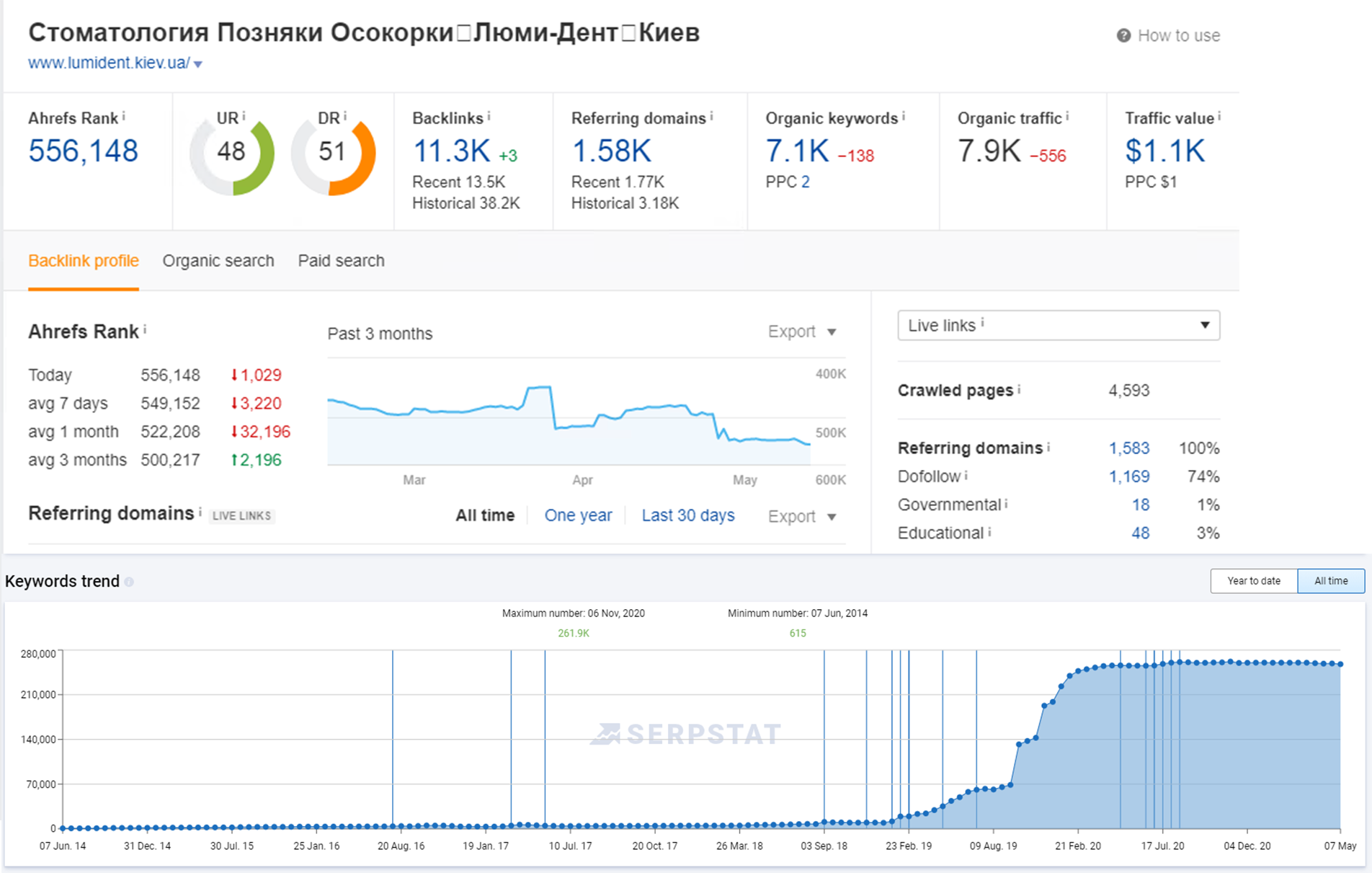
Роботи з розкручування стоматологічної клініки
- Робота за Scholarship
- Аудит сайту за YMYL
- Аудит Юзабіліті
- Технічний аудит
Просування медичного інтернет-магазину
- Аудит сайтів
- Аналіз юзабіліті на сайті
- Робота з посилального просування
- ТЗ з виправлення помилок
2. «Водяне» прокляття
Західні експерти з AI-етики називають це феноменом “Sycophancy” (Сикофанство або Догідливість). Дослідження, опубліковане на порталі Anthropic, підтверджує: моделі, що пройшли навчання з підкріпленням (RLHF), схильні погоджуватися з упередженнями користувача, навіть якщо вони невірні, щоб отримати “схвалення”. Це виливається в нескінченні ввічливі вступи («У сучасному світі цифрового маркетингу…») і підтвердження ваших же помилок. У тестах на чесність моделі частіше обирали “улесливу”, але невірну відповідь, ніж сухий факт, якщо відчували, що користувач цього очікує.
З нещодавніх прикладів — довго сидів і вивчав ТЗ для роботи, де потрібно було зробити реально дві речі — аналітику і кампанію в PMax на товари, але ТЗ було просто на 10 сторінок. Ви просите короткий аналіз, а отримуєте есе в стилі школяра, якому потрібно набрати обсяг слів.
- Проблема: Моделі навчені бути ввічливими і запобігливими. Це виливається в нескінченні вступи («У сучасному світі цифрового маркетингу важливість PMax кампаній важко переоцінити…») і висновки.
- Рішення: Жорсткі системні промти. Фрази «no yapping» (без балачок), «only raw data» (тільки сирі дані) або «відповідь почни відразу з пункту 1» стають обов’язковими атрибутами vibe-working.
Без ручного виправлення ІІ-тексти швидко стають впізнаваними через характерні вступні слова і структури. Пошуковики у 2026 році легко ідентифікують такі патерни, знижуючи охоплення «лінивим» ресурсам. І контент може містити фейки або нічого цінного, крім того, що і так відомо. Все тому, що ШІ не має особистого досвіду (Experience) і не може надати авторські кейси або експертні думки, які Google у 2026 році цінує вище, ніж будь-коли.
3. Амнезія контексту та Excel-сліпота
Незважаючи на заявлені контекстні вікна в мільйони токенів, моделі страждають вибірковою пам’яттю. Я тому ЗАВЖДИ починаю новий чат. Не забувайте, при створенні матеріалу він зазвичай бере топ-10 статей з пошуку і перефразовує їх, видаючи за унікальний контент — так що перевіряти потрібно через Copyleaks або наш інструмент Unmiss AI Content Detector.
Втрата контексту при довгому діалозі
- Втрата даних: Дослідники зі Стенфорда (разом з UC Berkeley) опублікували роботу, що стала знаменитою, про феномен “Lost in the Middle” (Втрачені посередині). Точність вилучення інформації висока на початку промту і в самому кінці. Але дані, що знаходяться в середині довгого контексту (наприклад, 50-й рядок в Excel-файлі зі 100), модель ігнорує або галюцинує.
- Ефект золотої рибки: До кінця довгого діалогу модель може забути інструкції, дані на початку.
- Лайфхак: Ніколи не «згодовуйте» моделі величезні масиви даних одним шматком без попередньої структури. Використовуйте RAG-системи (як NotebookLM) або розбивайте завдання на частини.
І перевіряйте. Системи обмежені базою, на якій вони вчилися, і можуть видавати упереджені або застарілі рекомендації. Автоматизація не означає «натиснув і забув»; на перевірку і редактуру (fact-checking) ШІ-контенту часто йде стільки ж часу, скільки на написання тексту з нуля.
4. Тональна глухота
ШІ поки що погано відчуває «вайб» бренду. Він часто скочується в те, що дизайн-критики називають “Corporate Memphis” в тексті — безликий, нудотно-позитивний стиль, характерний для LinkedIn.
- Спостереження: Експерти з контент-маркетингу зазначають, що тексти від GPT-4 часто перенасичені словами-маркерами на кшталт “unleash”, “landscape”, “game-changer”, “delve” (останнє стало мемом як ознака AI-тексту).
- Рішення: Використання Perplexity Pro для пошуку фактів і Claude 3.5 для стилізації (він краще імітує людські нюанси мови), але з жорсткою забороною на кліше.
Частина 2. Світла сторона: Що ШІ робить краще за людей (вже зараз)
Незважаючи на мінуси, є завдання, де нейромережі дають фору команді джуніорів. Секрет успіху — у використанні спеціалізованих інструментів, а не одного лише ChatGPT.
1. Аналітика конкурентів (Зв’язка SERanking + Gemini)
Це справжній game-changer для маркетологів. Замість ручного перебору сайтів:
- Робимо вивантаження з SERanking або SERPSTAT (ключі, трафік, позиції).
- Завантажуємо CSV в Gemini (у нього чудовий інтерпретатор даних).
- Використовуємо Deep Research для якісного аналізу.
- Результат: Структурована таблиця, де підсвічені не просто відмінності, а «білі плями» в стратегії конкурентів, куди можна вдарити своїм бюджетом.
2. Рев’ю коду (Claude — король розробки)
Поки OpenAI лідирує в загальних завданнях, Claude (особливо версії 3.5 Sonnet і Opus) став де-факто стандартом для програмістів. Опитування на Hacker News і Reddit (r/LocalLLaMA) показують, що розробники віддають перевагу Claude за “меншу кількість лінивого коду” і кращі здібності до рефакторингу в порівнянні з GPT-4o.
- Він не просто знаходить помилку, він пояснює чому цей шматок HTML/CSS зламає верстку в Safari.
- Vibe coding у дії: ви копіюєте «локшину» з коду, кидаєте в Claude і просите «зробити красиво і безпечно». У 9 з 10 випадків результат можна деплоїти в продакшн.
3. Генерація ТЗ з хаосу (NotebookLM)
Це, мабуть, найбільш недооцінене застосування.
- Сценарій: У вас є нотатки в телефоні, пара голосових повідомлень від клієнта, PDF з брендбуком і листування в Telegram.
- Рішення: Завантажуємо все це «добро» в NotebookLM від Google. Це RAG (Retrieval-Augmented Generation) система, яка працює тільки за вашими документами.
- Промт: «На основі цих джерел склади суворе технічне завдання для розробника на створення лендінгу».
- Підсумок: Ідеально структурований документ без галюцинацій (тому що джерело обмежене вашими файлами).
Спеціалізація моделей (Сильні сторони)
4. SEO-магія (Unmiss.com і розмітка)
Ручне прописування метатегів у 2026 році — це моветон. Західні SEO-експерти (наприклад, із Search Engine Journal) говорять про перехід від ключових слів до Semantic SEO (Смислового SEO).
- Спеціалізовані інструменти (наприклад, модуль AI в Unmiss.com) аналізують не просто ключові слова, а сенс контенту. Вони генерують Title і Description, які подобаються і Google, і людям (CTR зростає).
- Schema.org: Просити нейромережу написати JSON-LD розмітку для сторінки — це найшвидший спосіб отримати розширені сніпети у видачі. Головне — дати їй код сторінки (або скористатися парсером).
5. Пояснення складного простою мовою
Ідеальний кейс «перекладача з технічної на клієнтську».
- Ситуація: Програміст написав документацію до API, яку не розуміє навіть Project Manager.
- Дія: Використовуйте промт, заснований на “Feynman Technique” (Техніка Фейнмана): “Поясни цей концепт так, як ніби ти пояснюєш його 12-річній дитині, використовуючи аналогії з реального світу”.
- Результат: Клієнт задоволений, тому що нарешті зрозумів, за що платить гроші.
Частина 3. Vibe Working: Методологія нової продуктивності
Як зібрати це все в єдину систему? Відмовтеся від ідеї «одного вікна». Ваше робоче місце тепер виглядає як пульт управління польотами.
Стек «Менеджера нейромереж»
| Завдання | Інструмент (Рекомендація) | Чому? |
|---|---|---|
| Кодинг / Верстка | Claude 3.5 Sonnet / Opus | Краще розуміння контексту коду і менше багів. |
| Робота з великими даними / Google Таблиці | Gemini Advanced | Глибока інтеграція з екосистемою Google, величезне вікно контексту. |
| Пошук і фактчекінг | Perplexity Pro / Gemini Deep Research | Доступ до реального часу, посилання на джерела. |
| Структурування знань / ТЗ | NotebookLM | Працює суворо за завантаженими джерелами, нуль відсебеньок. |
| SEO та Метатеги | Unmiss.com / Specialized Tools | Аналіз контенту + знання алгоритмів ранжування. |
| Тексти / E-mail / Рерайт | ChatGPT (GPT-4o) | Хороша стилістична гнучкість (при правильному налаштуванні). |
Золоті правила Vibe Working
- Принцип перехресного допиту: Ніколи не вірте одній моделі у важливих питаннях. Якщо o3 видала статистику — попросіть Perplexity знайти джерело. Якщо Gemini написав код — попросіть Claude перевірити його на баги.
- Промт-інженерія мертва, хай живе контекст: Перестаньте шукати «чарівні промти». Замість цього вчіться збирати якісний контекст. Найкращий промт — це чітке ТЗ і приклади (Few-Shot Prompting).
- Правило 80/20: Нейромережа робить 80% рутини. Решту 20% часу ви витрачаєте не на створення з нуля, а на експертну оцінку і «докручування». Це і є vibe-working.
- Унікальність через синтез: Щоб не плодити контент-клон, використовуйте нейромережі для синтезу ідей. Попросіть дати 20 заголовків, виберіть 3 найкращі, змішайте їх і допишіть самі.
- Самонавивчайтеся. Тривала робота тільки з ШІ притупляє навички самого фахівця. Виникає ефект «сліпої довіри», коли редактор перестає помічати помилки через втому від величезних обсягів генерації.
- Не економте. На другому етапі — перевірки фактів — доводиться наймати другу (дорожчу і потужнішу) нейромережу для перевірки роботи першої. Це сильно здорожує інфраструктуру і вимагає складного налаштування метрик оцінки якості. Ну і в підсумку — якісні моделі (рівня GPT-4o або Claude 3.5 Sonnet) коштують дорого при масовій генерації. Спроба заощадити і використовувати дешеві локальні моделі (Llama-3 і т.д.) часто призводить до різкого падіння якості, що вимагає ще більше часу на ручну перевірку.
Висновок
Мені часто кажуть, вас ШІ замінить. І так, і ні. ШІ замінить тих, хто не розуміє, як ним користуватися. Але не замінить тих, хто зрозумів.
Сьогодні автоматизація — це не «заміна людини», а зміна її ролі. Основна складність змістилася з області «написати текст» в область «налаштувати пайплайн, забезпечити подачу чистих даних і організувати багаторівневий контроль якості». Той, хто не справляється з технічною стороною перевірки, отримує сайт, забитий «галюцинаціями», який швидко потрапляє під фільтри пошукових систем.
Ми стоїмо на порозі цікавого часу. ШІ не замінив нас, але він назавжди змінив те, як ми працюємо. Vibe Working — це відмова від перфекціонізму на користь швидкості та ітеративності.
Так, нейромережі галюцинують. Так, вони ллють воду. Але той, хто навчився фільтрувати цей потік і використовувати сильні сторони кожної конкретної моделі, отримує суперздібність: робити роботу цілого відділу самотужки за один вечір.
Головне — не забувати: ви тут бос. А вони — всього лише дуже розумні, але іноді п’яні стажери.
(3 оцінок, середнє: 5,00 з 5)
Підпишіться на розсилку
Будьте в курсі останніх новин та спеціальних пропозицій
Я із задоволенням відповім на них. Якщо вас цікавить просування вашого проєкту або консультація з розкрутки, я з радістю готовий поспілкуватися з вами.
Напишіть мені, будь ласка, зручним для вас способом.

