
Как проверить текст на ИИ
Узнай как получить огромный трафик

Сегодня тексты от искусственного интеллекта уже достигли того уровня, когда они почти неотличимы от того, что пишет человек. Но при внимательном анализе все еще ясно выступают текстовые признаки ГПТ. Их можно условно разделить на языковые формы, синтаксис и логику структуры.
GPT генерирует тексты, которые формально корректны, стилистически выровнены и логически связны. Это звучит как преимущество, но именно из-за этой «избыточной правильности» текст ИИ часто выглядит подозрительно ровным, стерильным и обезличенным.
Проблема действительно актуальна, и цифры не дадут соврать:
- 60% украинских компаний проверяют контент на ИИ.
- 85% ИИ-текстов содержат шаблонные фразы.
- 40% SEO-специалистов в Украине используют AI-детекторы.
- 90% ИИ-текстов имеют идеальную грамматику.
- По статистике SEOquick 25% сайтов получали санкции за ИИ-спам.
Если вы столкнулись с подобной проблемой, и волнуетесь, что ваш трафик под угрозой (или конкуренты выбились вперед за счет правильного ИИ, или вы переживаете, что с ИИ переборщили), то всегда можете отправить ваш сайт мне на анализ и получить план по продвижению своего проекта.
Также вы можете написать мне просто в соцсети удобным для вас способом.
Автоматические способы проверки на ИИ
Нам как только не приходилось придумывать, как проверять текст на ИИ, что пришлось создать свой собственный инструмент, который доступен по ссылке.
Как он работает? Очень просто. Вставляете текст, нажимаете “Анализировать” и смотрите, где контент написан ИИ и почему.
Сервис детально распишет, что, как и где ИИ написал и наследил.
Когда мы создавали этот инструмент, то юзали такие сервисы, как Copyleaks и Originality.ai. Мы думали, что никогда не сможем создать подобный сервис, пока не разобрались в логике их работы. И в их основе стоит просто анализ текста при помощи… ИИ!
И я захотел досконально изучить проблему, и вот решил поделиться, как мы научились определять текст, написан ли он при помощи ИИ или нет.
Типичные языковые формы, используемые GPT
GPT строит текст на основе статистически часто встречающихся оборотов и формулировок. Это делает речь похожей на человеческую, но ведёт к повторяющимся клише и обобщённому стилю.
| Признак | GPT | Человек |
| Структура | Идеально логичная | Может быть сбитой, импровизированной |
| Тон | Вежливый, академический | Эмоциональный, личностный |
| Переходы между абзацами | Через явные связки | Часто интуитивные |
| Ошибки | Отсутствуют | Иногда есть (даже намеренные) |
| Форма аргументации | По модели: тезис → обоснование → вывод | Может быть нелогичной, но убедительной |
GPT предпочитает более нейтральный, аккуратный язык. Стилистически он скорее похож на научно-популярный, при этом избегает сленга (если его специально не попросить — тогда его не остановить), эмоциональных оценок и личных обращений. Человек же чаще добавляет интонацию из контекста, смешивая стили.
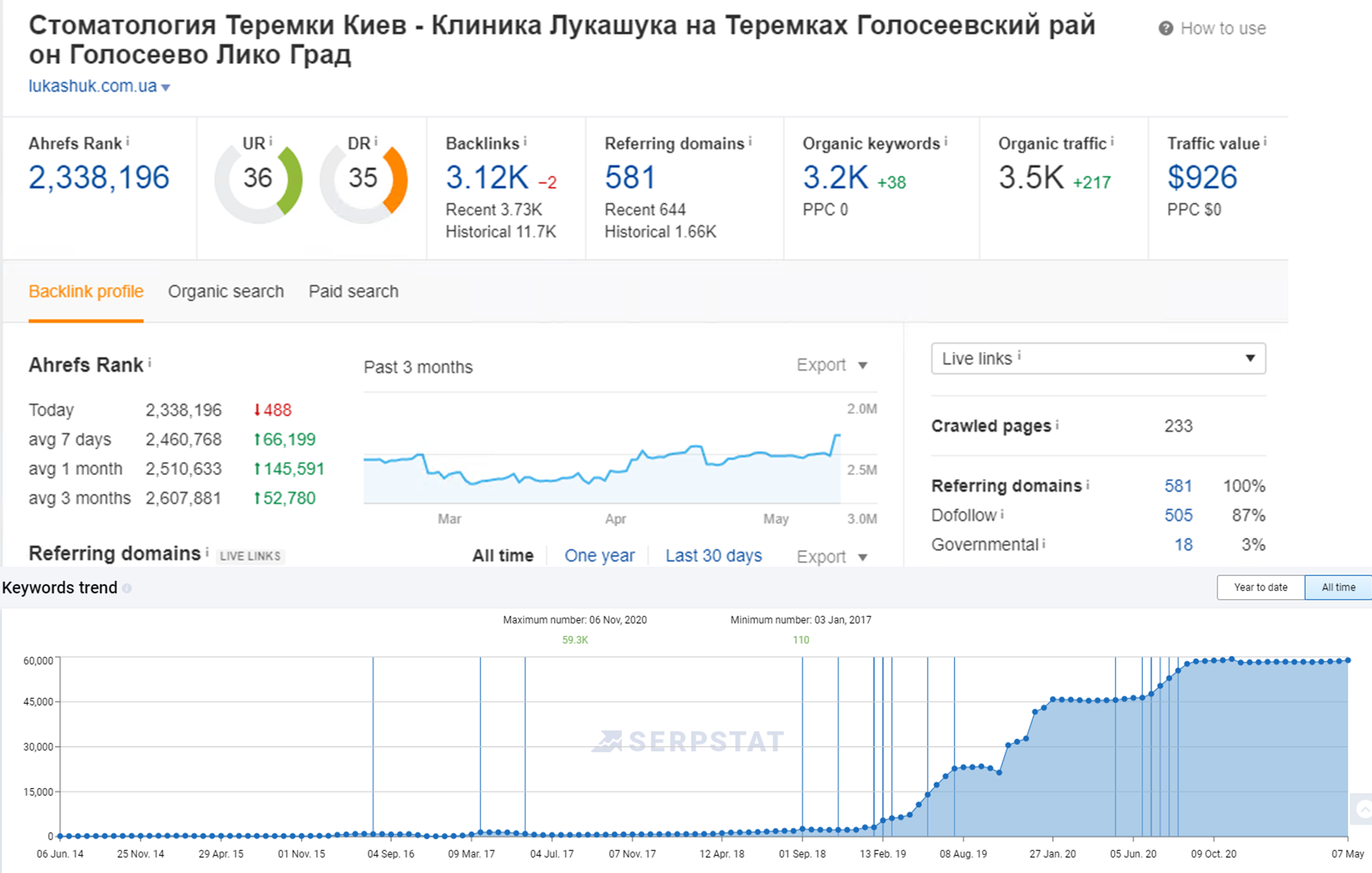
Продвижение медицинского сайта
- Составление контент плана
- Переработка страниц
- Постоянный контроль ошибок
- Ссылочные стратегии

SEO Продвижение для B2B
- Аудит сайта
- Внутренняя оптимизация
- Копирайтинг
- Статейные ссылки
- Ссылки на форумах
- Регистрация в каталогах
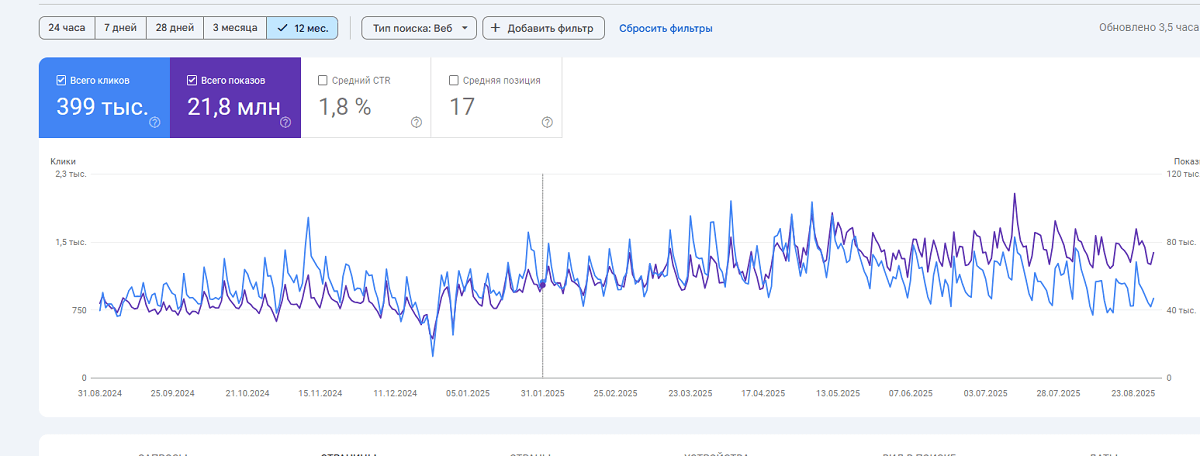
Продвижение интернет-магазина по Польше
- Техническая оптимизация
- Линкбилдинг
- Переписывание контента
- Работа с блогом
- Работа с адаптацией под GEO
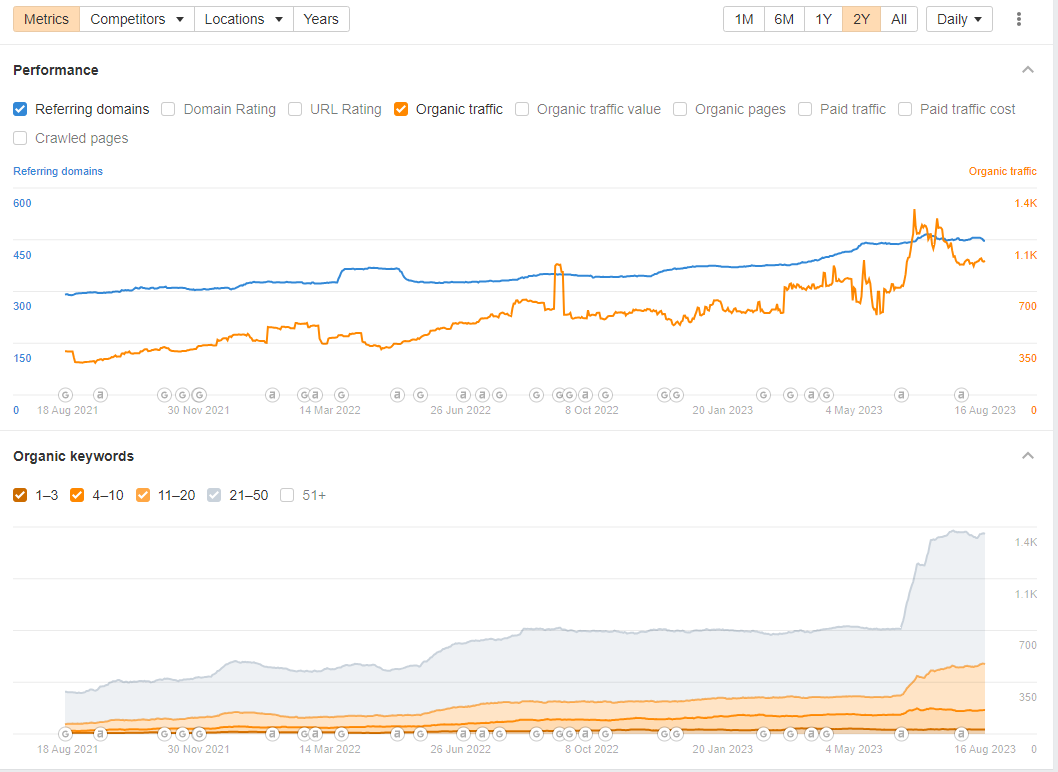
Продвижение Агентства недвижимости на Кипре
- Оптимизация контента на сайте
- Техническая оптимизация
- Анализ конкурентов
- Линкбилдинг
- Настройка контекстной рекламы
- PR продвижение
- Таргетинг в Facebook и Instagram

Настройка Facebook Ads для косметологической клиники в Израиле
- Жесткое ограничение гео и демографии
- Сегментация по языку и платежеспособности
- Плейсменты
Шаблонные вводные фразы
Такие фразы часто используются для старта абзаца и представляют собой универсальные шаблоны, не требующие конкретики.
У живого автора такие обороты встречаются значительно реже.
- В современном мире
- Не секрет, что
- Одним из ключевых аспектов является
- Стоит отметить, что
- Следует учитывать
- Существует мнение, что
- Важно понимать
- Перед тем как
- В то же время
- Таким образом
- В данной статье рассматривается
GPT также любит начинать предложения со сложностей и концептов. Это вид словесного мусора, упростить который желательно при очеловечивании текстов.
Это пример сразу “мусорной” SEO-воды, которую льет сейчас GPT.
Вот примеры этих “словечек”, по которым можно увидеть это в тексте.
- С учётом
- В рамках
- Многие считают
- Однако
- В условиях
- Исходя из
- На основании
- При рассмотрении
- С точки зрения
- В контексте
- В соответствии с
Такие формулировки сразу выдают ИИ, ну и еще – нечистых на руку архаичных копирайтеров, которые гребут за количество знаков в предложении.
Обобщённые модели утверждений
GPT часто пишет так, чтобы показать объёмность и учёт деталей, но на деле часто скрывает пустоту смысла. Обычно когда вы видите подобный контент, в нем не хватает кое-чего важного — ФАКТОВ. Такие речевые конструкции используются, когда информации, на которую GPT мог бы опереться, нет, но абзац нужно заполнить.
- Существует множество способов
- Многие считают, что
- Как правило, это зависит от контекста.
- Важно учитывать ряд факторов.
- Это эффективный способ
- Это основа
- Данный подход может быть эффективным.
- Следует обратить внимание
- Это особенно актуально в условиях
- Есть несколько точек зрения на этот вопрос
- Однозначного ответа не существует
- Каждый случай требует индивидуального подхода
Если вы видите что-то похожее в тексте, знайте, его писал ИИ с не очень умным автором. У человека всегда больше импровизации, метафор, неожиданностей.
Повторы однотипных шаблонов
Человек чаще вносит разнообразие в примыкающие фразы и не использует одни и те же концовки в каждом абзаце. GPT же старается всегда построить “логичный каркас” вывода, и подбить его “заключительным”, часто повторяющимся общую суть предложением.
- Это означает, что
- Таким образом
- В итоге
- Следовательно
- На основании
- В заключение отметим
- Исходя из сказанного
- Это подтверждает тот факт,
- Можно сделать вывод,
- Подводя итоги
И также GPT любит вставлять в предложение уточнение, словно пример-исключение. Вот типичные словечки:
- Тем не менее
- С другой стороны
- Как следствие
- Вместе с тем
- Важно помнить
Допустим, вы научили GPT не делать этого. Но есть все равно машинная логика построения текстов, и по ним он будет все равно создавать контент. Ее не разрушить — он по ней строит весь свой текст — он ведь отвечает на ваш вопрос.
Синтаксические паттерны GPT
Человек лажает. Использует иногда странную постановку предложений, вот как я сейчас. Редактор обычно хватается за голову, когда я пишу статьи и забываю и запятые, и много чего еще. А вот GPT избирает грамматически верные, четкие и логичные структуры предложений. Это приводит к следующим узнаваемым шаблонам.
Переходные конструкции между абзацами
Обычно
GPT любит связывать абзацы через:
- «Тем не менее»
- «С другой стороны»
- «Как следует из»
Это делает текст логичным, но слишком равным. Человек обычно переходит к новой мысли без явных маркеров.
Списки из трёх элементов
Часто текст любого списка начинается или с заголовка сразу, или вот с такого предложения.
- Текст должен быть полезным, структурированным и основанным на фактах
- Автор проанализировал проблему, подвел итоги и дал рекомендации
Но не только в списках проявляется любовь к числу 3.
Структурная правильность
Бог любит троицу, а GPT явно любит делить идеи на три элемента. Это удобно и логично, но в человеческой речи такая ритмика встречается реже.
Еще забавнее, когда в целом под каждый заголовок GPT генерирует примерно три текстовых блока. Один — вступление, второй — пояснение, третий — вывод.
То есть — GPT создает структурно «идеальные» тексты, и любовь к симметрии тут выражается еще в таких элементах, как:
- абзацы одной длины;
- каждый абзац начинается с вводной или темы;
- в конце — связка к следующему абзацу.
Я спросил — почему так? У самого GPT и он мне ответил.
GPT строит текст как хорошо структурированную статью — по учебнику:
- тезис — аргументы — вывод;
- нет отступлений, нет «провалов» в логике;
- нет «человеческих» колебаний или отклонений от темы.
У человека чаще абзацы неровные, логика может быть не завершена.
Выглядит примерно это так:
Тут я специально просил его избегать ИИ словечек, но логику машины не обмануть. Человек пишет хаотично, размеры абзацев могут сильно отличаться, да и скрины вставить человек может только адекватно, если что.
Чрезмерная вежливость и нейтральность
GPT маскирует суждение и старается избегать:
- категоричных заявлений;
- оценок вроде «это плохо», «это глупо»;
- слишком личных фраз.
К примеру, мне GPT наваял: “Некоторые пользователи могут считать данный подход недостаточно эффективным в определённых условиях”. А ведь можно сказать “это не работает”! У человека часто появляются эмоции, юмор, сомнение, импровизация.
Идеальная пунктуация и грамматика
GPT почти не делает ошибок:
- ставит все запятые;
- никогда не путает род/число;
- не допускает двусмысленности.
Человек часто ошибается или специально нарушает правила ради выразительности. За что меня очень “любит” мой редактор.
ТОП 20 признаков того, что текст написан в GPT
Распознавание GPT-сгенерированного текста
В наше время технологии искусственного интеллекта развиваются с невероятной скоростью, и одним из ярких примеров такого прогресса является GPT (Generative Pre-trained Transformer) — мощный инструмент для генерации текста. Однако возникает вопрос: как отличить статью, написанную человеком, от текста, сгенерированного GPT? Ответ прост — с помощью специального скрипта.
Спецсимволы и элементы, указывающие на GPT-генерацию
Один из способов распознавания текста, созданного с помощью GPT, — это обращение внимания на определенные спецсимволы и элементы структуры текста. Хотя эти признаки могут быть не всегда очевидны, они могут включать в себя необычные повторения, специфические обороты речи или даже определенные ошибки, которые характерны для машинного обучения.
—
Этот символ представляет собой тире, элемент пунктуации, который не так часто встречается в текстах статей (речь идет о символе —). Его использование в письменной речи обычно ограничивается одним-двумя случаями на весь текст, что делает его довольно редким гостем.
Однако, когда речь заходит о GPT и его способности генерировать текст, ситуация меняется. GPT может включить в свой текст до 19 таких символов! Так что, если вы насчитаете кучу тире в этом тексте, не ругайте меня.
« и »
Этот символ используется для создания кавычек типа « ». Эти кавычки, известные как французские или елочки, применяются в текстах, в том числе в литературных произведениях, научных статьях и официальных документах. Они придают тексту элегантность и способствуют лучшему восприятию цитат или прямой речи читателями.
А вот в повседневной переписке и в вебе чаще предпочитаются более простые и удобные английские кавычки ” “. Эти кавычки вводятся на клавиатуре быстрее и проще, что делает их идеальными для использования в социальных сетях, мессенджерах и электронной почте. А вот GPT просто ОБОЖАЕТ такие кавычки
“ и ”
Второй символ GPT кавычек (“ ”). Такие кавычки еще более несвойственны в написании текстов людьми. Я никогда не видел в здоровой жизни эти кавычки на сайтах. И если увижу, сразу заподозрю ИИ.
→ и ←
Этот символ вообще нестандартный для текста. Это вроде просто стрелки (→ ←), но они вообще несвойственные для здорового текста.
Я такие стрелки стабильно ловлю в текстах, которые мне присылает GPT. Если, правда, я хочу нарисовать стрелку, я делаю это колхозно. Ставлю дефис и знак больше. Вот так ->
<0xa0>
<0xa0> — это обычный неразрывный пробел (другие названия: u00A0 или ). Используется для форматирования текста, и ничего секретного в нем нет. Но обычные авторы контента его не используют в обычной жизни. Мы ставим просто пробелы и не паримся.
’
Это пример неправильного апострофа (символ ’). Вот который использует человек – ‘. Такой апостроф в коде выглядит так же.
…
Или многоточие (символ ) — очень редко используется при написании человеком. Мы обычно просто три раза ставим точку (вот так)…
 
Тонкая неразрывная пауза. Человек подобный код не использует вовсе! Об этом символе вообще узнал случайно.
Обработка одиночных спецсимволов
Символы типа © (©) и ® (®) обычно редко встречаются в контенте, но GPT сможет их легко вставить. Обычный человек не найдет их на клавиатуре никогда. Обычно он напишет (с) или (R) в чистом тексте.
Особенность в написании кода
GPT всегда чётко закрывает каждый тег (<p>, <li>, <ul>, <h2>, <h3>, <div>, <hr>). Да, обычно, когда мы копируем из гугл документа, эти коды закрыты часто одинаково. Но небольшие огрехи всегда встречаются!
Механическая верстка списков и вложенных элементов
GPT всегда расставляет <ul><li><p>Текст</p></li></ul> вместо просто <ul><li>Текст</li></ul>.
Это выдает машинную аккуратность.
Горизонтальная линия разделитель
Обычно тег выглядит так – <div><hr /></div>
Хотя браузеры понимают и <hr>, GPT всегда вставляет закрывающий слэш по стандарту XHTML. Человек тем более не использует этот тег — <div><hr /></div> для вставки горизонтальной линии. Наличие такой горизонтальной линии — на уровне каминг-аута перед Google.
Кавычки вокруг атрибутов
GPT всегда оформляет все атрибуты с кавычками (” “), даже когда это не обязательно (<option value=1> будет автоматически преобразовано в <option value=”1”>). Человек вручную такие атрибуты никогда не добавляет.
data-start и data-end
В ЦЕЛОМ все аттрибуты Data никто в H1-H6 не ставит, но GPT всегда их вставляет куда угодно. Будь то текст или что-то подобное. Ни в одном списке или параграфе у человека этих символов НЕТ. Примеры: <h1 data-start=”494″ data-end=”519″>Вот скрипт, как у тебя:</h1>
data-pm-slice
Атрибут для внутренних меток редактора (откуда копируется текст). Это атрибут, который вставляется редакторами вроде ProseMirror (используется в некоторых чатах, например, в ChatGPT на базе редакторов с форматированием). Он нужен для внутренней разметки текста (отрезки, блоки) и абсолютно не нужен в чистом HTML-коде. Человек вручную такие атрибуты никогда не добавляет.
data-spread=”false”
Атрибут для контроля свёрнутости/развёрнутости списков, нужен только редактору. Это атрибут, который обычно появляется в <ul>, <ol>, <li> и <p> в коде из таких редакторов. Он говорит о “разворачивании” или “сворачивании” вложений внутри списка — также служебный атрибут для редакторов. Человек вручную такие атрибуты никогда не добавляет.
✅ Emoji в заголовках H1-Н6
Данный элемент вообще несвойственен, да и не поощряется. Увидеть такое в контенте — считай засветиться, что ты все генерировал в GPT. Даже не думая. Любой Emoji в H1-H6 — сразу ошибка!
</strong>
Этот тег обычно используется всегда, но люди его применяют нечасто. С его помощью мы выделяем то, на чем следует сфокусировать внимание в обычном параграфе. Но GPT обожает его добавлять вот в такие места:
- Первые пару слов после параграфа обычно никто не использует жирным. Чаще всего — мы можем выделить важный термин — который расшифрован в этом же предложении. Но GPT может жирным выделить.
- Слово, выделенное жирным, еще имеет двоеточие — и после двоеточия идет пояснение. Обычно в списках. Человек так не делает.
Как Google определяет, является ли контент сгенерированным ИИ
Я решил копнуть не очень стандартную тему. Пришлось помучать Гугл, соцсети и даже ИИ. И вот что вышло.
Google не раскрывает точных деталей своих алгоритмов, но исследования сеошников в X и официальные заявления в блоге Гугл позволяют составить картину того, как Google обрабатывает контент, созданный ИИ.
Как оказалось, Google не использует специализированный детектор ИИ-контента, а полагается на свои собственные системы оценки качества и борьбы со спамом, такие как SpamBrain и алгоритмы ранжирования (подробности в руководстве).
Вот цитата:
Мы фокусируемся на качестве контента, а не на том, как он был произведен
(источник)
Если единого метода нет, то какие есть? Ведь сайтам за ИИ генережку прилетает…
Методы, которые Google использует для анализа контента
Я нашел 4 метода, за счет которых Гугл находит проблемный контент, включая потенциально сгенерированный ИИ. Вот ключевые направления:
Анализ языковых шаблонов
Google находит (причем без усилий — у него есть Gemini) “характерные для ИИ” шаблоны текста, такие как повторяющиеся синтаксические конструкции, избыточная формальность или отсутствие естественных нюансов. Мы их уже все перечислили в нашей статье.
Google может использовать алгоритмы машинного обучения для анализа структуры текста, грамматики и синтаксиса, выявляя признаки, которые отличают ИИ от человеческого письма.
Метрики поведения пользователей
Google анализирует, как юзеры взаимодействуют с контентом: время на странице, уровень отказов, кликабельность. Эти метрики Гуглу сливают Хром, Аналитика и телефоны на Андроид (об этом мы говорили на вебинаре про Суд).
Если страница не удерживает внимание, это сигнал о низком качестве, независимо от того, кто её создал. Это четко указывается в их руководстве.
Проверка на спам и массовое производство
Google активно борется со спамом. Если контент создаётся массово без добавления ценности, он подпадает под определение “спамного автоматически генерируемого контента”. Это подробно описано в политике Google по спаму:
Мы рассматриваем как спам контент, созданный с помощью автоматизации без значительной ценности для пользователей, например, сгенерированные тексты для манипуляции поисковыми рейтингами.
(источник)
Поэтому ключевым моментом будет не “массовая выгрузка контента на страницы, которые до этого пустовали”. А немного постепенная выкладка контента — не выгружайте одним махом сотню тысяч страниц.
Система полезного контента
Введённое в 2022 году обновление полезного контента (HCU) направлено на продвижение материалов, созданных для людей, а не для поисковых алгоритмов. Если ИИ-контент не отвечает интересам аудитории, он может быть понижен в выдаче.
Итого, 4 критерия. И нигде нет жесткого % ИИ сгенерированного или написанного человеком. Важно понимать, что Google не запрещает использование ИИ для создания контента.
Напротив, компания подчёркивает, что способ создания не имеет значения, если результат полезен. В том же блоге Google Search Central говорится:
Автоматизация, включая ИИ, использовалась для создания контента годами — от новостных сводок до прогнозов погоды. Если она применяется для создания полезного контента, это не противоречит нашим правилам.
(источник)
Однако есть чёткие границы. Если ИИ используется для массового производства низкокачественного контента, например, для заполнения сайта тысячами страниц с перефразированным текстом ради ключевых слов, это может быть расценено как нарушение.
Как обойти проверку ИИ и исправить ошибки?
Озвученный метод на сегодня — просто мастхев в нашем бизнес-процессе.
Сейчас я при помощи него уже начал писать статьи. Да, он позволяет создавать контент, который лишен черт AI-контента.
Но он лишен души. Не выглядит, как симфония, не пахнет шедевром. А пахнет чем-то другим.
Так вот, чтобы не быть Мидасом наоборот, я собрал отличный рецепт, как обработать перед тем, как контент будет создан по уже заранее собранному ТЗ (а как собирать ТЗ — я уже писал огромную статью — поэтому для ТЗ сначала скормите ее в ИИ как текст, а потом задайте тему, вашу ЦА и попросите сочинить ТЗ).
Суть следующая:
- Первоначально отправляем эту статью GPT, чтобы он избегал этих ошибок. Обучаем его.
- Собираем ТЗ на статью.
- Спрашиваем у ИИ, каких данных для материала ему не хватает, чтобы она выглядела как экспертный материал, написанный человеком.
Пример запроса
Я хочу написать статью по этому ТЗ. Прошу тебя проанализировать, каких данных тебе не хватает для выполнения рекомендаций EEAT — может фактов, кейсов, моего личного мнения и по каким вопросам.
ТЗ прилагаю ниже
<вставить ТЗ>
Перед написанием статьи задай мне вопросы, на которые я тебе предоставлю развернутые ответы — и их используй в статье.
В ТЗ должны быть:
- Тема.
- Метаданные статьи.
- Структура заголовков.
- Направленность на нужную аудиторию (описать ее).
- Объем статьи в количестве слов.
После отправки ответов попросите ИИ написать статью с учетом предложенных материалов. Допишите это после ответов:
Прошу на основе предоставленных данных написать статью согласно техническому заданию.
Я рекомендую все же использовать Grok или хотя бы платный GPT, базовый GPT не справлялся на момент написания этого гайда — с задачей.
Затем после написания статьи проверяем ее на AI Detector (требует регистрации, дает бесплатную проверку, сам тул недорогой, смотрим Pricing).
И затем отправляем следующим сообщением ошибки.
Я проверил текст на AI генерацию и обнаружил следующие ошибки.
<вкладываете все, что идет в Detailed analysis в отчете>
Прошу исправить формулировки на естественные, согласно рекомендациям, не уменьшая объем статьи
Результат вас очень удивит.
P.S. Тул свежий, поэтому на сайте Unmiss сейчас очень вкусные скидки -60% — за 39$ вы получаете 150 проверок на ИИ в месяц (если возьмете на год).
(3 оценок, среднее: 5,00 из 5)
Подпишитесь на рассылку
Будьте в курсе последних новостей и спецпредложений
Я с удовольствием отвечу вам на них. Если вас интересует продвижение своего проекта, консультация по раскрутке, я с радостью буду рад пообщаться с вами
Напишите мне пожалуйста удобным вам способом

