
Як перевірити текст на ШІ
Дізнайтеся, як отримати величезний трафік

Сьогодні тексти від штучного інтелекту вже досягли того рівня, коли вони майже не відрізняються від того, що пише людина. Але при уважному аналізі все ще ясно виступають текстові ознаки ГПТ. Їх можна умовно розділити на мовні форми, синтаксис і логіку структури.
GPT генерує тексти, які формально коректні, стилістично вирівняні та логічно зв’язні. Це звучить як перевага, але саме через цю “надлишкову правильність” текст ШІ часто виглядає підозріло рівним, стерильним і знеособленим.
Проблема справді актуальна, і цифри не дадуть збрехати:
- 60% українських компаній перевіряють контент на ШІ.
- 85% ШІ-текстів містять шаблонні фрази.
- 40% SEO-фахівців в Україні використовують AI-детектори.
- 90% ШІ-текстів мають ідеальну граматику.
- За статистикою SEOquick 25% сайтів отримували санкції за ШІ-спам.
Якщо ви зіткнулися з подібною проблемою, і хвилюєтеся, що ваш трафік під загрозою (або конкуренти вибилися вперед завдяки правильному ШІ, або ви переживаєте, що з ШІ переборщили), то завжди можете надіслати ваш сайт мені на аналіз та отримати план з просування свого проєкту.
Також ви можете написати мені просто в соцмережі зручним для вас способом.
Автоматичні способи перевірки на ШІ
Нам як тільки не доводилося вигадувати, як перевіряти текст на ШІ, що довелося створити свій власний інструмент, який доступний за посиланням.
Як він працює? Дуже просто. Вставляєте текст, натискаєте “Аналізувати” і дивитеся, де контент написаний ШІ і чому.
Сервіс детально розпише, що, як і де ШІ написав і наслідив.
Коли ми створювали цей інструмент, то юзали такі сервіси, як Copyleaks і Originality.ai. Ми думали, що ніколи не зможемо створити подібний сервіс, поки не розібралися в логіці їхньої роботи. І в їхній основі стоїть просто аналіз тексту за допомогою… ШІ!
І я захотів досконально вивчити проблему, і ось вирішив поділитися, як ми навчилися визначати текст, написаний він за допомогою ШІ чи ні.
Типові мовні форми, що використовуються GPT
GPT будує текст на основі оборотів і формулювань, які статистично часто зустрічаються. Це робить мову схожою на людську, але веде до повторюваних кліше та узагальненого стилю.
| Ознака | GPT | Людина |
| Структура | Ідеально логічна | Може бути збитою, імпровізованою |
| Тон | Ввічливий, академічний | Емоційний, особистісний |
| Переходи між абзацами | Через явні зв’язки | Часто інтуїтивні |
| Помилки | Відсутні | Іноді є (навіть навмисні) |
| Форма аргументації | За моделлю: теза → обґрунтування → висновок | Може бути нелогічною, але переконливою |
GPT віддає перевагу більш нейтральній, акуратній мові. Стилістично він радше схожий на науково-популярну, при цьому уникає сленгу (якщо його спеціально не попросити — тоді його не зупинити), емоційних оцінок і особистих звернень. Людина ж частіше додає інтонацію з контексту, змішуючи стилі.

Налаштування лідогенерації через Facebook/Instagram (Meta Ads)
- Сегментація аудиторій
(Facebook Ads) - Креативи та формати
- Оптимізація бюджету
- Структура рекламного облікового запису
- Сегментація аудиторій
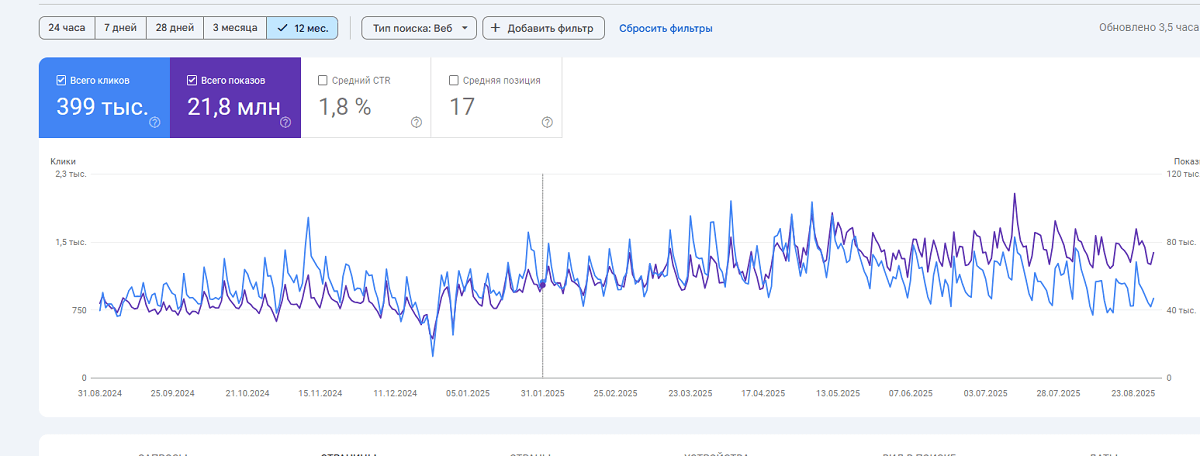
Просування інтернет-магазину в Польщі
- Технічна оптимізація
- Лінкбілдинг
- Переписування контенту
- Робота з блогом
- Робота з адаптацією під GEO

Просування сайту сервісу ремонту побутової техніки
- SEO-просування
- контент
- лінкбілдинг
- локальне SEO
Просування відеоконтенту форумами
- Пошук форумів
- Розігрівання гілок
- Публікація роликів
- Відповіді на запитання

Налаштування Facebook Ads для косметологічної клініки в Ізраїлі
- Жорстке обмеження гео та демографії
- Сегментація з мови та платоспроможності
- Плейсменти
Шаблонні вступні фрази
Такі фрази часто використовуються для старту абзацу і являють собою універсальні шаблони, які не потребують конкретики.
У живого автора такі звороти зустрічаються значно рідше.
- У сучасному світі
- Не секрет, що
- Одним із ключових аспектів є
- Варто зазначити, що
- Слід враховувати
- Існує думка, що
- Важливо розуміти
- Перед тим як
- Водночас
- Таким чином
- У цій статті розглядається
GPT також любить починати речення зі складнощів і концептів. Це вид словесного сміття, спростити яке бажано під час олюднення текстів.
Це приклад одразу “сміттєвої” SEO-води, яку ллє зараз GPT.
Ось приклади цих “слівець”, за якими можна побачити це в тексті.
- З урахуванням
- У рамках
- Багато хто вважає
- Однак
- В умовах
- Виходячи з
- На підставі
- При розгляді
- З погляду
- У контексті
- Відповідно до
Такі формулювання одразу видають ШІ, ну і ще — нечистих на руку архаїчних копірайтерів, які гребуть за кількість знаків у реченні.
Узагальнені моделі тверджень
GPT часто пише так, щоб показати об’ємність і врахування деталей, але на ділі часто приховує порожнечу сенсу. Зазвичай коли ви бачите подібний контент, у ньому не вистачає дечого важливого — ФАКТІВ. Такі мовні конструкції використовуються, коли інформації, на яку GPT міг би спертися, немає, але абзац потрібно заповнити.
- Існує безліч способів
- Багато хто вважає, що
- Як правило, це залежить від контексту
- Важливо враховувати низку чинників
- Це ефективний спосіб
- Це основа
- Цей підхід може бути ефективним
- Слід звернути увагу
- Це особливо актуально в умовах
- Є кілька поглядів на це питання
- Однозначної відповіді не існує
- Кожен випадок вимагає індивідуального підходу
Якщо ви бачите щось схоже в тексті, знайте, його писав АІ з не дуже розумним автором. У людини завжди більше імпровізації, метафор, несподіванок.
Повтори однотипних шаблонів
Людина частіше урізноманітнює фрази, що приєднуються, і не використовує одні й ті самі кінцівки в кожному абзаці. GPT же намагається завжди побудувати “логічний каркас” висновку, і підбити його “завершальним” реченням, що часто повторює загальну суть.
- Це означає, що
- Таким чином
- У підсумку
- Отже
- На підставі
- Насамкінець зазначимо
- Виходячи зі сказаного
- Це підтверджує той факт
- Можна зробити висновок
- Підбиваючи підсумки
І також GPT любить вставляти в речення уточнення, немов приклад-виняток. Ось типові слівця:
- Однак
- З іншого боку
- Як наслідок
- Разом з тим
- Важливо пам’ятати
Припустимо, ви навчили GPT не робити цього. Але є все одно машинна логіка побудови текстів, і за нею він буде все одно створювати контент. Її не зруйнувати — він за нею будує весь свій текст — адже він відповідає на ваше запитання.
Синтаксичні патерни GPT
Людина лажає. Використовує іноді дивну постановку речень, ось як я зараз. Редактор зазвичай хапається за голову, коли я пишу статті і забуваю і коми, і багато чого ще. А от GPT обирає граматично правильні, чіткі та логічні структури речень. Це призводить до таких впізнаваних шаблонів.
Перехідні конструкції між абзацами
Зазвичай
GPT любить пов’язувати абзаци через:
- “Однак”
- “З іншого боку”
- “Як випливає з”
Це робить текст логічним, але занадто рівним. Людина зазвичай переходить до нової думки без явних маркерів.
Списки з трьох елементів
Часто текст будь-якого списку починається або із заголовка одразу, або ось із такого речення.
- Текст має бути корисним, структурованим і заснованим на фактах
- Автор проаналізував проблему, підбив підсумки і дав рекомендації
Але не тільки в списках проявляється любов до числа 3.
Структурна правильність
Бог любить трійцю, а GPT явно любить ділити ідеї на три елементи. Це зручно і логічно, але в людській мові така ритміка зустрічається рідше.
Ще кумедніше, коли загалом під кожен заголовок GPT генерує приблизно три текстові блоки. Один — вступ, другий — пояснення, третій — висновок.
Тобто — GPT створює структурно “ідеальні” тексти, і любов до симетрії тут виражається ще в таких елементах, як:
- абзаци однієї довжини;
- кожен абзац починається зі вступного або теми;
- наприкінці — зв’язка до наступного абзацу.
Я запитав — чому так? У самого GPT і він мені відповів.
GPT будує текст як добре структуровану статтю — за підручником:
- теза — аргументи — висновок;
- немає відступів, немає “провалів” у логіці;
- немає “людських” коливань або відхилень від теми.
У людини частіше абзаци нерівні, логіка може бути не завершена.
Виглядає приблизно це так:
Тут я спеціально просив його уникати ШІ слівець, але логіку машини не обдурити. Людина пише хаотично, розміри абзаців можуть сильно відрізнятися, та і скрини вставити людина може тільки адекватно, якщо що.
Надмірна ввічливість і нейтральність
GPT маскує судження і намагається уникати:
- категоричних заяв;
- оцінок на кшталт “це погано”, “це нерозумно”;
- занадто особистих фраз.
Наприклад, мені GPT наваяв: “Деякі користувачі можуть вважати цей підхід недостатньо ефективним у певних умовах”. Але ж можна сказати “це не працює”! У людини часто з’являються емоції, гумор, сумнів, імпровізація.
Ідеальна пунктуація та граматика
GPT майже не робить помилок:
- ставить усі коми;
- ніколи не плутає рід/число;
- не допускає двозначності.
Людина часто помиляється або спеціально порушує правила заради виразності. За що мене дуже “любить” мій редактор.
ТОП 20 ознак того, що текст написаний у GPT
Розпізнавання GPT-згенерованого тексту
У наш час технології штучного інтелекту розвиваються з неймовірною швидкістю, і одним із яскравих прикладів такого прогресу є GPT (Generative Pre-trained Transformer) — потужний інструмент для генерації тексту. Однак виникає питання: як відрізнити статтю, написану людиною, від тексту, згенерованого GPT? Відповідь проста — за допомогою спеціального скрипта.
Спецсимволи та елементи, що вказують на GPT-генерацію
Один зі способів розпізнавання тексту, створеного за допомогою GPT, – це звернення уваги на певні спецсимволи та елементи структури тексту. Хоча ці ознаки можуть бути не завжди очевидні, вони можуть містити незвичайні повторення, специфічні звороти мови або навіть певні помилки, які характерні для машинного навчання.
—
Цей символ являє собою тире, елемент пунктуації, який не так часто зустрічається в текстах статей (йдеться про символ -). Його використання в письмовій мові зазвичай обмежується одним-двома випадками на весь текст, що робить його досить рідкісним гостем.
Однак, коли мова заходить про GPT і його здатність генерувати текст, ситуація змінюється. GPT може включити у свій текст до 19 таких символів! Тож, якщо ви нарахуєте купу тире в цьому тексті, не сваріть мене.
« і »
Цей символ використовується для створення лапок типу « ». Ці лапки, відомі як французькі або ялинки, застосовуються в текстах, зокрема в літературних творах, наукових статтях та офіційних документах. Вони надають тексту елегантності та сприяють кращому сприйняттю цитат або прямої мови читачами.
А ось у повсякденному листуванні та в інтернеті частіше віддають перевагу простішим і зручнішим англійським лапкам ” “. Ці лапки вводяться на клавіатурі швидше і простіше, що робить їх ідеальними для використання в соціальних мережах, месенджерах і електронній пошті. А ось GPT просто ОБОЖНЮЄ такі лапки.
“ і ”
Другий символ GPT лапок (” “). Такі лапки ще більш невластиві в написанні текстів людьми. Я ніколи не бачив у здоровому житті ці лапки на сайтах. І якщо побачу, одразу запідозрю ШІ.
→ і ←
Цей символ взагалі нестандартний для тексту. Це ніби просто стрілки (→ ←), але вони взагалі невластиві для здорового тексту.
Я такі стрілки стабільно ловлю в текстах, які мені надсилає GPT. Якщо, правда, я хочу намалювати стрілку, я роблю це колгоспно. Ставлю дефіс і знак більше. Ось так ->
<0xa0>
<0xa0> — це звичайний нерозривний пробіл (інші назви: u00A0 або ). Використовується для форматування тексту, і нічого секретного в ньому немає. Але звичайні автори контенту його не використовують у звичайному житті. Ми ставимо просто пробіли і не паримося.
’
Це приклад неправильного апострофа (символ ‘). Ось який використовує людина – ‘. Такий апостроф у коді має такий самий вигляд.
…
Або три крапки (символ ) — дуже рідко використовується при написанні людиною. Ми зазвичай просто тричі ставимо крапку (ось так)…
 
Тонка нерозривна пауза. Людина подібний код не використовує зовсім! Про цей символ узагалі дізнався випадково.
Обробка одиночних спецсимволів
Символи типу © (©) і ® (®) зазвичай рідко зустрічаються в контенті, але GPT зможе їх легко вставити. Звичайна людина не знайде їх на клавіатурі ніколи. Зазвичай вона напише (с) або (R) у чистому тексті.
Особливість у написанні коду
GPT завжди чітко закриває кожен тег (<p>, <li>, <ul>, <h2>, <h3>, <div>, <hr>). Так, зазвичай, коли ми копіюємо з гугл документа, ці коди закриті часто однаково. Але невеликі огріхи завжди зустрічаються!
Механічна верстка списків і вкладених елементів
GPT завжди розставляє <ul><li><p>Текст</p></li></ul> замість просто <ul><li>Текст</li></ul>.
Це видає машинну акуратність.
Горизонтальна лінія роздільник
Зазвичай тег має такий вигляд – <div><hr /></div>
Хоча браузери розуміють і <hr>, GPT завжди вставляє закриваючий слеш за стандартом XHTML. Людина тим більше не використовує цей тег — <div><hr /></div> для вставки горизонтальної лінії. Наявність такої горизонтальної лінії — на рівні камінг-ауту перед Google.
Лапки навколо атрибутів
GPT завжди оформляє всі атрибути з лапками (” “), навіть коли це не обов’язково (<option value=1> буде автоматично перетворено на <option value=”1”>). Людина вручну такі атрибути ніколи не додає.
data-start і data-end
В ЦІЛОМУ всі атрибути Data ніхто в H1-H6 не ставить, але GPT завжди їх вставляє куди завгодно. Будь то текст або щось подібне. У жодному списку або параграфі у людини цих символів НЕМАЄ. Приклади: <h1 data-start=”494″ data-end=”519″>Ось скрипт, як у тебе:</h1>
data-pm-slice
Атрибут для внутрішніх міток редактора (звідки копіюється текст). Це атрибут, який вставляється редакторами на кшталт ProseMirror (використовується в деяких чатах, наприклад, у ChatGPT на базі редакторів із форматуванням). Він потрібен для внутрішньої розмітки тексту (відрізки, блоки) і абсолютно не потрібен у чистому HTML-коді. Людина вручну такі атрибути ніколи не додає.
data-spread=”false”
Атрибут для контролю згорнутості/розгорнутості списків, потрібен тільки редактору. Це атрибут, який зазвичай з’являється в <ul>, <ol>, <li> і <p> в коді з таких редакторів. Він говорить про “розгортання” або “згортання” вкладень всередині списку — також службовий атрибут для редакторів. Людина вручну такі атрибути ніколи не додає.
✅ Emoji в заголовках H1-Н6
Цей елемент взагалі невластивий, та й не заохочується. Побачити таке в контенті — вважай засвітитися, що ти все генерував у GPT. Навіть не думаючи. Будь-який Emoji в H1-H6 — одразу помилка!
</strong>
Цей тег зазвичай використовується завжди, але люди його застосовують нечасто. З його допомогою ми виділяємо те, на чому слід сфокусувати увагу у звичайному параграфі. Але GPT обожнює його додавати ось у такі місця:
- Перші пару слів після параграфа зазвичай ніхто не використовує жирним. Найчастіше — ми можемо виділити важливий термін — який розшифровано в цьому ж реченні. Але GPT може жирним виділити.
- Слово, виділене жирним, ще має двокрапку — і після двокрапки йде пояснення. Зазвичай у списках. Людина так не робить.
Як Google визначає, чи є контент згенерованим ШІ
Я вирішив копнути не дуже стандартну тему. Довелося помучити Гугл, соцмережі і навіть ШІ. І ось що вийшло.
Google не розкриває точних деталей своїх алгоритмів, але дослідження сеошників в X і офіційні заяви в блозі Гугл дають змогу скласти картину того, як Google обробляє контент, створений ШІ.
Як виявилося, Google не використовує спеціалізований детектор ШІ-контенту, а покладається на свої власні системи оцінювання якості та боротьби зі спамом, як-от SpamBrain і алгоритми ранжування (подробиці у посібнику).
Ось цитата:
Ми фокусуємося на якості контенту, а не на тому, як він був зроблений
(джерело)
Якщо єдиного методу немає, то які є? Адже сайтам за ШІ генерування прилітає…
Методи, які Google використовує для аналізу контенту
Я знайшов 4 методи, завдяки яким Гугл знаходить проблемний контент, включно з потенційно згенерованим ШІ. Ось ключові напрямки:
Аналіз мовних шаблонів
Google знаходить (причому без зусиль — у нього є Gemini) “характерні для ШІ” шаблони тексту, як-от синтаксичні конструкції, що повторюються, надмірна формальність або відсутність природних нюансів. Ми їх уже всі перерахували в нашій статті.
Google може використовувати алгоритми машинного навчання для аналізу структури тексту, граматики і синтаксису, виявляючи ознаки, які відрізняють ШІ від людського письма.
Метрики поведінки користувачів
Google аналізує, як користувачі взаємодіють з контентом: час на сторінці, рівень відмов, клікабельність. Ці метрики Гуглу зливають Хром, Аналітика і телефони на Андроїд (про це ми говорили на вебінарі про Суд).
Якщо сторінка не утримує увагу, це сигнал про низьку якість, незалежно від того, хто її створив. Це чітко вказується в їхньому посібнику
Перевірка на спам і масове виробництво
Google активно бореться зі спамом. Якщо контент створюється масово без додавання цінності, він підпадає під визначення “спамного автоматично генерованого контенту“. Це детально описано в політиці Google щодо спаму:
Ми розглядаємо як спам контент, створений за допомогою автоматизації без значної цінності для користувачів, наприклад, згенеровані тексти для маніпуляції пошуковими рейтингами.
(джерело)
Тому ключовим моментом буде не “масове вивантаження контенту на сторінки, які до цього пустували”. А трохи поступове викладання контенту — не вивантажуйте одним махом сотню тисяч сторінок.
Система корисного контенту
Введене 2022 року оновлення корисного контенту (HCU) спрямоване на просування матеріалів, створених для людей, а не для пошукових алгоритмів. Якщо ШІ-контент не відповідає інтересам аудиторії, він може бути знижений у видачі.
Разом, 4 критерії. І ніде немає жорсткого % ШІ згенерованого або написаного людиною. Важливо розуміти, що Google не забороняє використання ШІ для створення контенту.
Навпаки, компанія підкреслює, що спосіб створення не має значення, якщо результат корисний. У тому ж блозі Google Search Central йдеться:
Автоматизація, включно зі ШІ, використовувалася для створення контенту роками – від новинних зведень до прогнозів погоди. Якщо вона застосовується для створення корисного контенту, це не суперечить нашим правилам.
(джерело)
Однак є чіткі межі. Якщо ШІ використовується для масового виробництва низькоякісного контенту, наприклад, для заповнення сайту тисячами сторінок із перефразованим текстом заради ключових слів, це може бути розцінено як порушення.
Як обійти перевірку ШІ та виправити помилки?
Озвучений метод на сьогодні — просто мастхев у нашому бізнес-процесі.
Зараз я за допомогою нього вже почав писати статті. Так, він дає змогу створювати контент, який позбавлений рис AI-контенту.
Але він позбавлений душі. Не виглядає, як симфонія, не пахне шедевром. А пахне чимось іншим.
Так ось, щоб не бути Мідасом навпаки, я зібрав чудовий рецепт, як опрацювати перед тим, як контент буде створено за вже заздалегідь зібраним ТЗ (а як збирати ТЗ — я вже писав величезну статтю — тому для ТЗ спочатку згодуйте її в ШІ як текст, а потім задайте тему, вашу ЦА і попросіть скласти ТЗ).
Суть така:
- Спочатку надсилаємо цю статтю GPT, щоб він уникав цих помилок. Навчаємо його.
- Збираємо ТЗ на статтю.
- Запитуємо у ШІ, яких даних для матеріалу йому бракує, щоб вона мала вигляд експертного матеріалу, написаного людиною.
Приклад запиту
Я хочу написати статтю за цим ТЗ. Прошу тебе проаналізувати, яких даних тобі не вистачає для виконання рекомендацій EEAT — може фактів, кейсів, моєї особистої думки і з яких питань.
ТЗ додаю нижче
<вставити ТЗ>
Перед написанням статті постав мені запитання, на які я тобі надам розгорнуті відповіді – і їх використовуй у статті.
У ТЗ мають бути:
- Тема.
- Метадані статті.
- Структура заголовків.
- Спрямованість на потрібну аудиторію (описати її).
- Обсяг статті в кількості слів.
Після надсилання відповідей попросіть ШІ написати статтю з урахуванням запропонованих матеріалів. Допишіть це після відповідей:
Прошу на основі наданих даних написати статтю згідно з технічним завданням.
Я рекомендую все ж використовувати Grok або хоча б платний GPT, базовий GPT не справлявся на момент написання цього гайда — із завданням.
Потім після написання статті перевіряємо її на AI Detector (вимагає реєстрації, дає безплатну перевірку, сам тул недорогий, дивимося Pricing).
І потім відправляємо наступним повідомленням помилки.
Я перевірив текст на AI генерацію і виявив такі помилки.
<вкладаєте все, що йде в Detailed analysis у звіті>
Прошу виправити формулювання на природні, згідно з рекомендаціями, не зменшуючи обсяг статті
Результат вас дуже здивує.
P.S. Тул свіжий, тому на сайті Unmiss зараз дуже смачні знижки -60% — за 39$ ви отримуєте 150 перевірок на ШІ на місяць (якщо візьмете на рік).
(2 оцінок, середнє: 5,00 з 5)
Підпишіться на розсилку
Будьте в курсі останніх новин та спеціальних пропозицій
Я із задоволенням відповім на них. Якщо вас цікавить просування вашого проєкту або консультація з розкрутки, я з радістю готовий поспілкуватися з вами.
Напишіть мені, будь ласка, зручним для вас способом.

